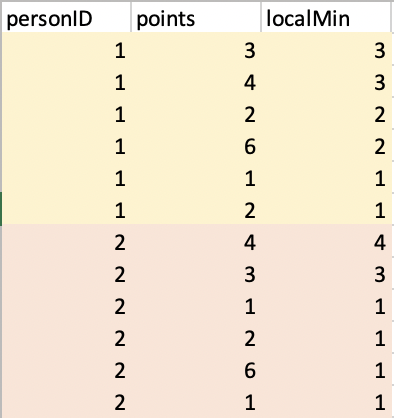
I am working with a pandas dataframe where I have the following two columns: "personID" and "points". I would like to create a third variable ("localMin") which will store the minimum value of the column "points" at each point in the dataframe as compared with all previous values in the "points" column for each personID (see image below).
Does anyone have an idea how to achieve this most efficiently? I have approached this problem using shift() with different period sizes, but of course, shift is sensitive to variations in the sequence and doesn't always produce the output I would expect.
Thank you in advance!
CodePudding user response:
Use groupby.cummin:
df['localMin'] = df.groupby('personID')['points'].cummin()
Example:
df = pd.DataFrame({'personID': list('AAAAAABBBBBB'),
'points': [3,4,2,6,1,2,4,3,1,2,6,1]
})
df['localMin'] = df.groupby('personID')['points'].cummin()
output:
personID points localMin
0 A 3 3
1 A 4 3
2 A 2 2
3 A 6 2
4 A 1 1
5 A 2 1
6 B 4 4
7 B 3 3
8 B 1 1
9 B 2 1
10 B 6 1
11 B 1 1