I have 5 million rows of daily transactions data in a column format of (year, month, day of the month, hour of the day, product that is purchased): I created this data frame as an example (please note that the original data is not ordered as I have given in this example and the range of date spreads over a span of 4 years.):
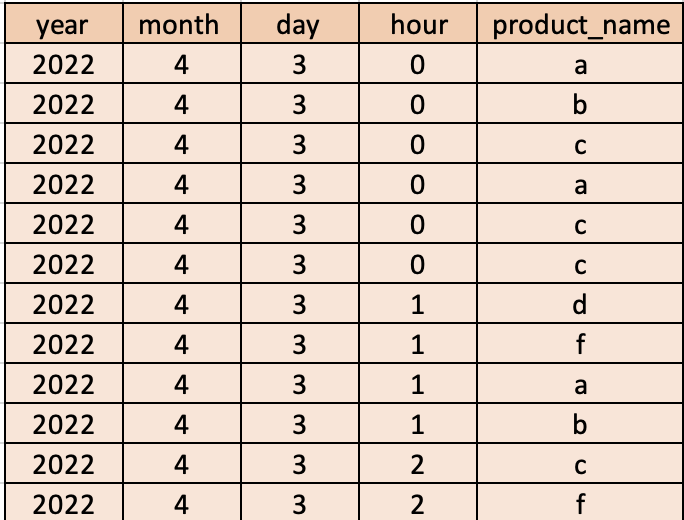
all_product_names = c("a","b","c","d","e","f","g","h","i")
my_table <- data.frame(year = c(2022,2022,2022,2022,2022,2022,2022,2022,2022,2022,2022,2022),
month = c(rep(4,12)),
day = c(rep(3,12)),
hour = c(0,0,0,0,0,0,1,1,1,1,2,2),
product_name = c("a","b","c","a","c","c","d","f","a","b","c","f") )
My desired output is a table where for a given time instance (a specific combination of year-month-day-hour) count of all product purchases are extended into the table as columns. "all_product_names" variable gives you a list of all the products that exist. Notice that not every time instance has all products purchased, for those instances, the "count table" value for that product must be zero. Here is what I am trying to get my output grouping to look like:

Using sqldf I have tried to group by product so that I get the count of product_name for every time instance, however It does not count into account of products that do not exist for every instance. And also I need to convert the row format into columns as indicated above in the solution table example.
xx <-sqldf('SELECT year,month,day,hour,product_name,COUNT(product_name) FROM my_table GROUP BY product_name,hour,day,month,year
ORDER BY product_name ASC')
Also as a note I do not have to use sqldf library. Thank you for your time!
CodePudding user response:
library(tidyverse)
my_table %>%
count(year, month, day, hour, product_name) %>%
pivot_wider(names_from = product_name, values_from = n, values_fill = 0)