Update: so I'm messing around with the two files, I copied the data from DOB column from the 2nd file to the 1st file to make the files look visually identical. However I notice some really interesting behaviour when using Ctrl F in Microsoft Excel. When I leave the search box blank in the first file it finds no matches. However when I repeat the same operation with the 2nd file it finds 21 matches from each cell between E1 to G7. I suppose somehow there are some blank/invisible cells in the 2nd file - and that's what's causing read_excel to behave differently.
My goal is to simply execute the pandas read_excel function. However, I'm running into a very strange situation in which I am trying to run pandas.read_excel on two very similar excel files but am getting substantially different results.
Code
import pandas
data1 = pandas.read_excel(r'D:\User Files\Downloads\Programming\stackoverflow\test_1.xlsx')
print(data1)
data2 = pandas.read_excel(r'D:\User Files\Downloads\Programming\stackoverflow\test_2.xlsx')
print(data2)
Output
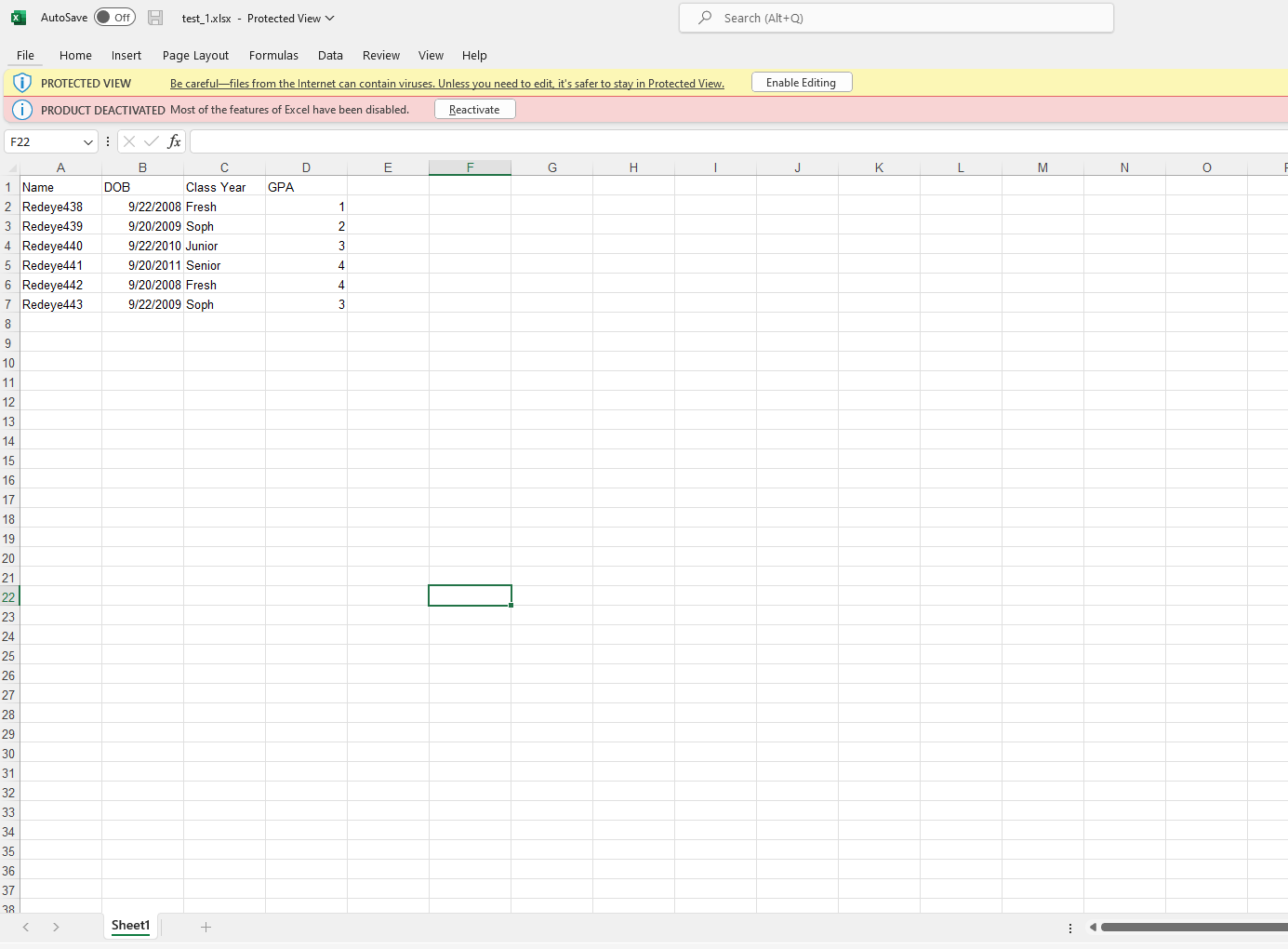
Name DOB Class Year GPA
0 Redeye438 2008-09-22 Fresh 1
1 Redeye439 2009-09-20 Soph 2
2 Redeye440 2010-09-22 Junior 3
3 Redeye441 2011-09-20 Senior 4
4 Redeye442 2008-09-20 Fresh 4
5 Redeye443 2009-09-22 Soph 3
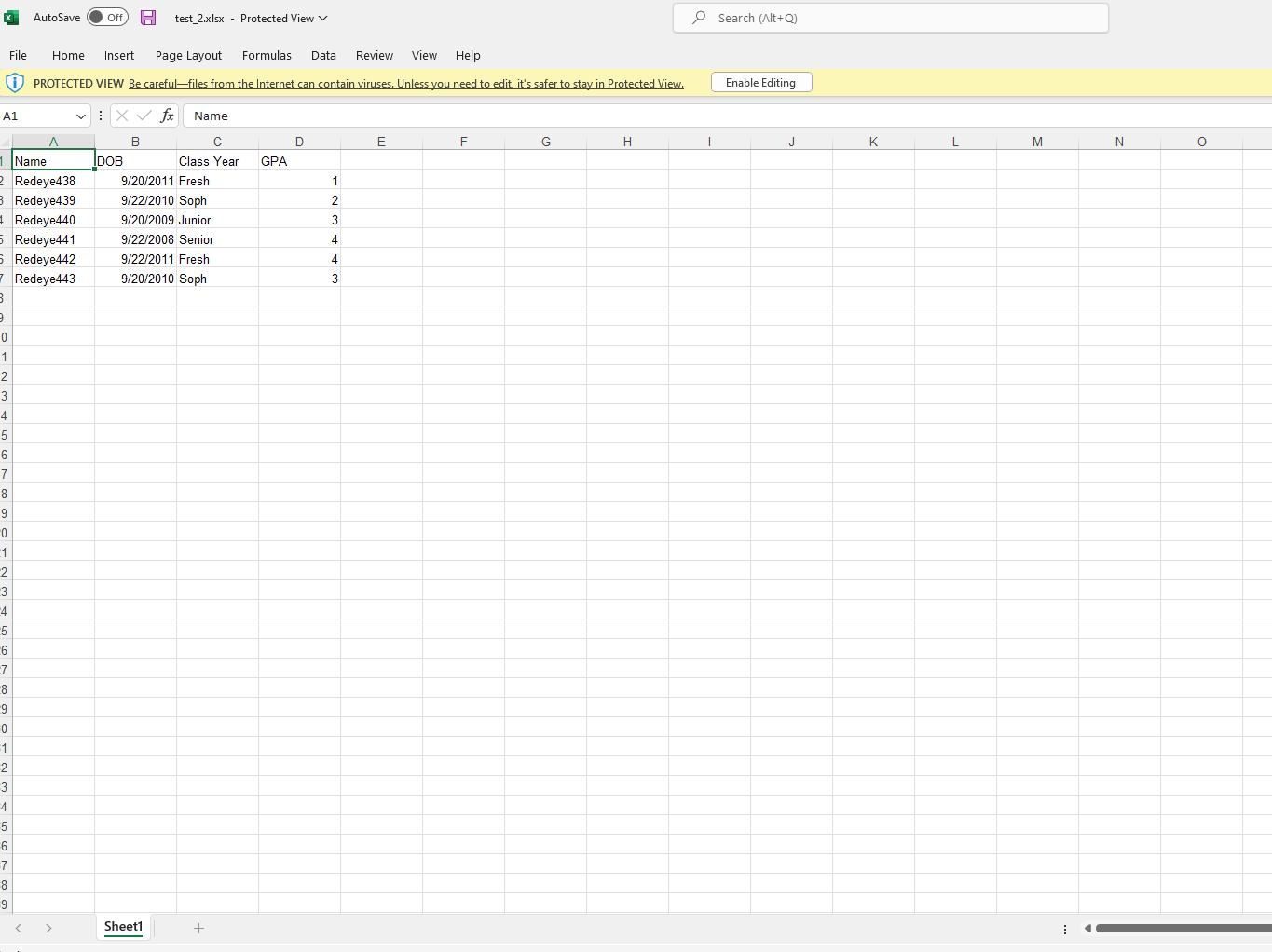
Name DOB Class Year GPA
Redeye438 2011-09-20 Fresh 1 NaN NaN NaN
Redeye439 2010-09-22 Soph 2 NaN NaN NaN
Redeye440 2009-09-20 Junior 3 NaN NaN NaN
Redeye441 2008-09-22 Senior 4 NaN NaN NaN
Redeye442 2011-09-22 Fresh 4 NaN NaN NaN
Redeye443 2010-09-20 Soph 3 NaN NaN NaN
Why are the columns mapped incorrectly for data2?
The excel files in question (the only difference is the data in the DOB column):
CodePudding user response:
It looks like you're using an older version of Pandas because I can't reproduce the issue on the latest version.
import pandas as pd
pd.show_versions()
INSTALLED VERSIONS
------------------
python : 3.10.5.final.0
python-bits : 64
OS : Windows
OS-release : 10
pandas : 1.5.0
As you can see below, the columns of data2 are mapped correctly.
import pandas as pd
data1 = pd.read_excel(r"C:\Users\abokey\Downloads\test_1.xlsx")
print(data1)
data2 = pd.read_excel(r"C:\Users\abokey\Downloads\test_2.xlsx")
print(data2)
Name DOB Class Year GPA
0 Redeye438 2008-09-22 Fresh 1
1 Redeye439 2009-09-20 Soph 2
2 Redeye440 2010-09-22 Junior 3
3 Redeye441 2011-09-20 Senior 4
4 Redeye442 2008-09-20 Fresh 4
5 Redeye443 2009-09-22 Soph 3
Name DOB Class Year GPA
0 Redeye438 2011-09-20 Fresh 1
1 Redeye439 2010-09-22 Soph 2
2 Redeye440 2009-09-20 Junior 3
3 Redeye441 2008-09-22 Senior 4
4 Redeye442 2011-09-22 Fresh 4
5 Redeye443 2010-09-20 Soph 3
However, you're right because the format of the two Excel files are not the same. In fact, when looking at test2.xlsx more carefully, this one seems to carry 7x3 blank cells (rows/cols). The latest version of pandas seems to handle this kind of Excel file since the empty cells are ignored when calling