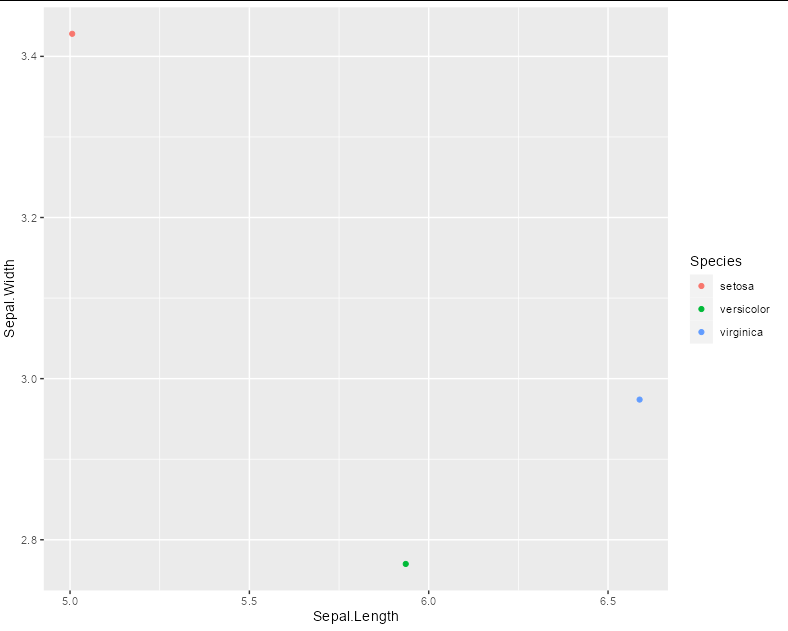
I can make the following plot very easily by computing the group means using dplyr, but is there way to do it entirely within ggplot2 without preprocessing the data, using stat_<something>?
library(tidyverse)
iris |>
group_by(Species) |>
summarise(
Sepal.Length = mean(Sepal.Length),
Sepal.Width = mean(Sepal.Width)
) |> ggplot()
geom_point(aes(x = Sepal.Length, y = Sepal.Width, color = Species))
stat_summary seems to summarize only at identical x or y values, and stat_bin doesn't work across discrete variables, but is there another stat_* for this? I've found stat_centroid from ggh4x but I'm looking for something built-in.
Edit: to be clear about my goals, I'm looking to avoid the duplication of the x/y/color column names if possible!
CodePudding user response:
The closest you can get, I think, is to embed the aggregation inside the stat_summary call by using a function as the data 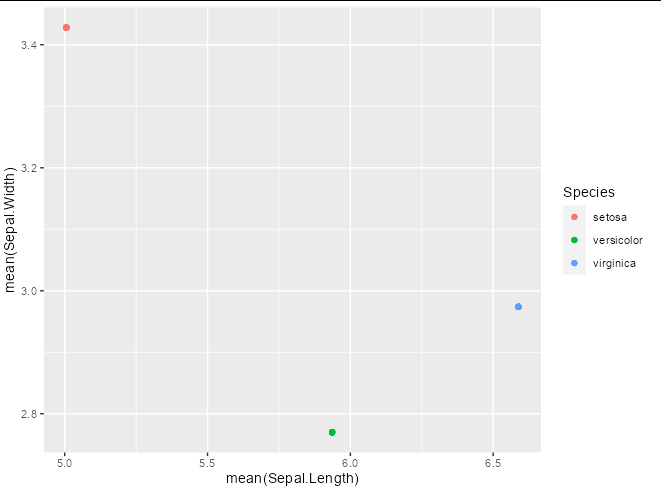
An alternative would be to pass a little summary data frame to the points layer using summarize_all
ggplot(iris, aes(Sepal.Length, Sepal.Width, color = Species))
geom_point(data = summarize_all(group_by(iris, Species), mean))