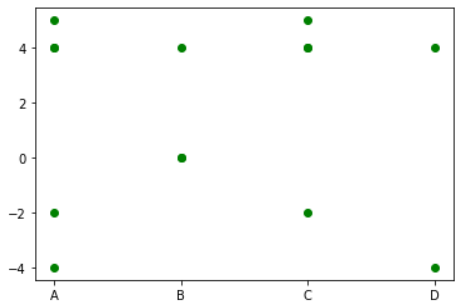
My aim is to show the negative data points (related to the Y-axis) in red, those values that are at zero in gray, and only the positive values in green
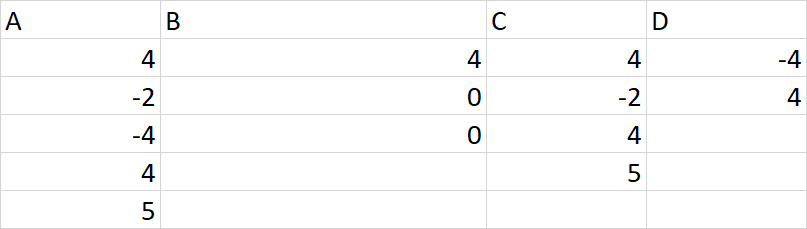
This is a simplified dataset of my issue:
Here is my current code:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data = pd.read_excel('data.xlsx')
plt.plot([data.A, data.B,data.C, data.D], 'o', c= 'g')
plt.xticks([0,1,2,3], ['A', 'B', 'C', 'D'])
plt.yticks(np.arange(-4, 6, step=2))
I hope someone can help me with this.
Thanks a lot!
CodePudding user response:
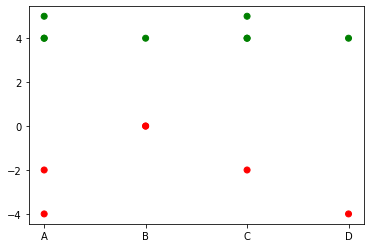
To assign a color to each entry, you will need to first stack() the dataframe so that each column will have the x values (A,B,C,D) and y would be the actual values. Then assign a color to each row and plot. The updated code is below.
df=data.stack().reset_index().drop(columns=['level_0']) #Stack data and remove unnecessary column
df.rename(columns={'level_1':'x', 0:'val'}, inplace=True) #Rename for easy identification
df['color'] = ["green" if i > 0 else "red" for i in df['val']] #Create color column
plt.scatter(df.x, y=df.val, c= df.color) #Plot with color = color column
plt.xticks([0,1,2,3], ['A', 'B', 'C', 'D'])
plt.yticks(np.arange(-4, 6, step=2))
CodePudding user response:
Thanks Michael,
i only had to adjust the if-statement with "grey if zero", and this is my perfect solution:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data = pd.read_excel('data.xlsx')
df=data.stack().reset_index().drop(columns=['level_0']) #Stack data and
#remove unnecessary column
df.rename(columns={'level_1':'x', 0:'val'}, inplace=True) #Rename for
# easy identification
df['color'] = ["green" if i > 0 else ("grey" if i == 0 else "red") for i
in df['val']] #Create color column
plt.scatter(df.x, y=df.val, c= df.color) #Plot with color = color column
plt.xticks([0,1,2,3], ['A', 'B', 'C', 'D'])
plt.yticks(np.arange(-4, 6, step=2))
{kind=link}