import numpy as np
import pandas as pd
data = {'Scheme': ['A', 'A', 'A', 'A', 'A'], 'Fuel_remaining': [5, 5, 5, 5, 5], 'correction': [0.25, 0.333333333, 0.44, 0.44, 0.44]}
df = pd.DataFrame(data)
df['fuel_usage'] = df['Fuel_remaining']*df['correction']
Above is small snippet. I wish to have correct fuel_usage for each row, in above I am making a mistake i.e in first row the fuel usage is 5*0.25 = 1.25, this need to be removed from Fuel remaining when computing for second row. The same way for row 3, need to remove fuel usage for row 1 and row 2 and so on.... If the pandas dataframe is huge, does it make sense to compute one row at a time use shift and then compute second row and so on? Or there can be better way?
Ideal output would be this (Not what I am getting in above snippet):
data = {'Scheme': ['A', 'A', 'A', 'A', 'A'], 'fuel_usage': [1.25, 1.25, 1.1, 0.616, 0.355], 'correction': [0.25, 0.333333333, 0.44, 0.44, 0.44]}
df = pd.DataFrame(data)
CodePudding user response:
We can update fuel usuage with simple loop; Try this;
fuel_usage = []
for i in range(0,df.shape[0]):
if i == 0:
num = df["Fuel_remaining"][i] * df['correction'][i]
fuel_usage.append(num)
else:
num = (df["Fuel_remaining"][i] - num) * df['correction'][i]
fuel_usage.append(num)
num = sum(fuel_usage)
df["fuel_usage"] = fuel_usage
del df["Fuel_remaining"]
Output of df;
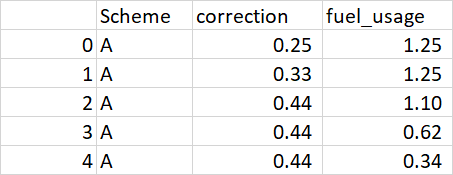
Hope this Helps...
CodePudding user response:
It's a bit of a mathematical answer, but hope you follow me.
Let's call the remaining fuel: f_0, ..., f_n, corrections c_0, ..., c_n and fuel usage u_0, ..., u_n. Notice that the usage is the fuel times the correction at row i. And the remaining fuel at row i is the fuel at row i-1 minus the usage at row i-1.
The formula for u_i is as follows:
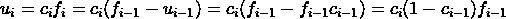
This can be further reduced to: u_i = c_i(1-c_{i-1})* ... *(1-c_0)f_0 which depends only on the corrections and the initial fuel. By doing:
df['times'] = (1 - df['correction']).cumprod().shift().fillna(1)
We compute the factor (1-c_{i-1})* ... *(1-c_0) at row i such that we can compute the fuel usage column by multiplying the intitial fuel with the column times and correction:
fuel = 5
df['fuel_usage'] = fuel * df.times * df.correction
Output:
Scheme Fuel_remaining correction times fuel_usage
0 A 5 0.250000 1.0000 1.25000
1 A 5 0.333333 0.7500 1.25000
2 A 5 0.440000 0.5000 1.10000
3 A 5 0.440000 0.2800 0.61600
4 A 5 0.440000 0.1568 0.34496