I have a dataset which i splitted to 80-20% training and test set. On the trainset I do k-fold cross validation and get the mean of the accuracies. However, it is not clear to me how should I apply this result to my original testset?
#Splitting Training & Test dataset
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
#Standartisation scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train[:,:] = sc.fit_transform(X_train[:,:])
X_test[:,:] = sc.transform(X_test[:,:])
#Trainign the SVM model on the Training set
from sklearn.svm import SVC
classifier = SVC(kernel='rbf', random_state=0)
classifier.fit(X_train, y_train)
#Making the Confusion Matrix of SVM model
from sklearn.metrics import confusion_matrix, accuracy_score
y_pred = classifier.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
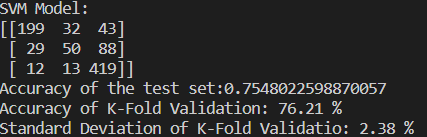
print("SVM Model: ")
print(cm)
print('Accuracy of the test set:' str(accuracy_score(y_test, y_pred)))
#applying k-Fold cross validation
from sklearn.model_selection import cross_val_score
accuracies = cross_val_score(estimator=classifier, X=X_train, y=y_train, cv=15)
print('Accuracy of K-Fold Validation: {:.2f} %'.format(accuracies.mean()*100))
print('Standard Deviation of K-Fold Validatio: {:.2f} %'.format(accuracies.std()*100))
CodePudding user response:
You can either save all the models for each fold, for example, if you have 5 folds, you then have 5 models. Run your test set through each model and ensemble the predictions.
OR
You might have been using kfold to determine the best hyperparameters. In this case, retrain using these best hyperparams with the ENTIRE data set (train and validation) and then evaluate on the external test set. Its not clear from your question if you are doing train/test splitting or train/validation/test so be careful you don't overlap the sets.
CodePudding user response:
There are two issues here:
- If you're using cross-validation, do not scale the data first. Instead, you need to add a scaler to a pipeline, and do the cross-validation using the pipeline. This is because during cross-validation, each training step needs the data scaled only to the current training set, not to the entire dataset.
- In cross-validation, you do not actually train the model yourself. Instead,
sklearnis going to train it for you inside the cross-validation loop. Once you have selected the model you're going to use, then you will train the model on all your data.
So here's one way to approach your task:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.model_selection import cross_val_score, cross_val_predict, cross_validate
X, y = make_classification(n_features=2, n_redundant=0, n_informative=2, random_state=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
sc = StandardScaler()
clf = SVC(kernel='rbf', random_state=0)
# Make a pipeline model that scales and estimates.
pipe = make_pipeline(sc, clf)
# Make predictions during cross-validation.
y_pred = cross_val_predict(pipe, X_train, y_train, cv=10, n_jobs=-1)
cm = confusion_matrix(y_train, y_pred)
score = accuracy_score(y_train, y_pred)
print("SVM Model: ")
print(cm)
print('Validation accuracy on training set: {:.2f}%'.format(score*100))
# Alternatively, use cross_val_score.
accuracies = cross_val_score(estimator=pipe, X=X_train, y=y_train, cv=10)
print()
print('Accuracy of k-fold validation: {:.2f}%'.format(accuracies.mean()*100))
print('Standard deviation of k-fold validation: {:.2f}%'.format(accuracies.std()*100))
This results in:
SVM Model:
[[41 0]
[ 3 36]]
Validation accuracy on training set: 96.25%
Accuracy of k-fold validation: 96.25%
Standard deviation of k-fold validation: 5.73%
The key thing about cross_val_predict is that it makes predictions during cross-validation, when each fold of the data is the validation set. Then it puts all the predictions together to give you validation predictions for the full dataset, so you can use sklearn's various scoring tool on that.
The nice thing about cross_val_score is that you see all the scores from each fold. Notice that they average to the same thing as the overall dataset: 96.25%. But now you can also get the variance, which is important because this informs you a bit about the possible prediction variance you can expect from the model on unseen data in the future.
What about the test data?
You should not test your model against X_test and y_test until the very end of the model selection workflow. Only when you have set all the hyperparameters in the model, e.g. the C, kernel, and gamma hyperparameters in this particular algorithm, should you check how that model does on the test data. To put it another way: do not use test for model tuning, only for performance estimation.