I am trying to scrape the price of this 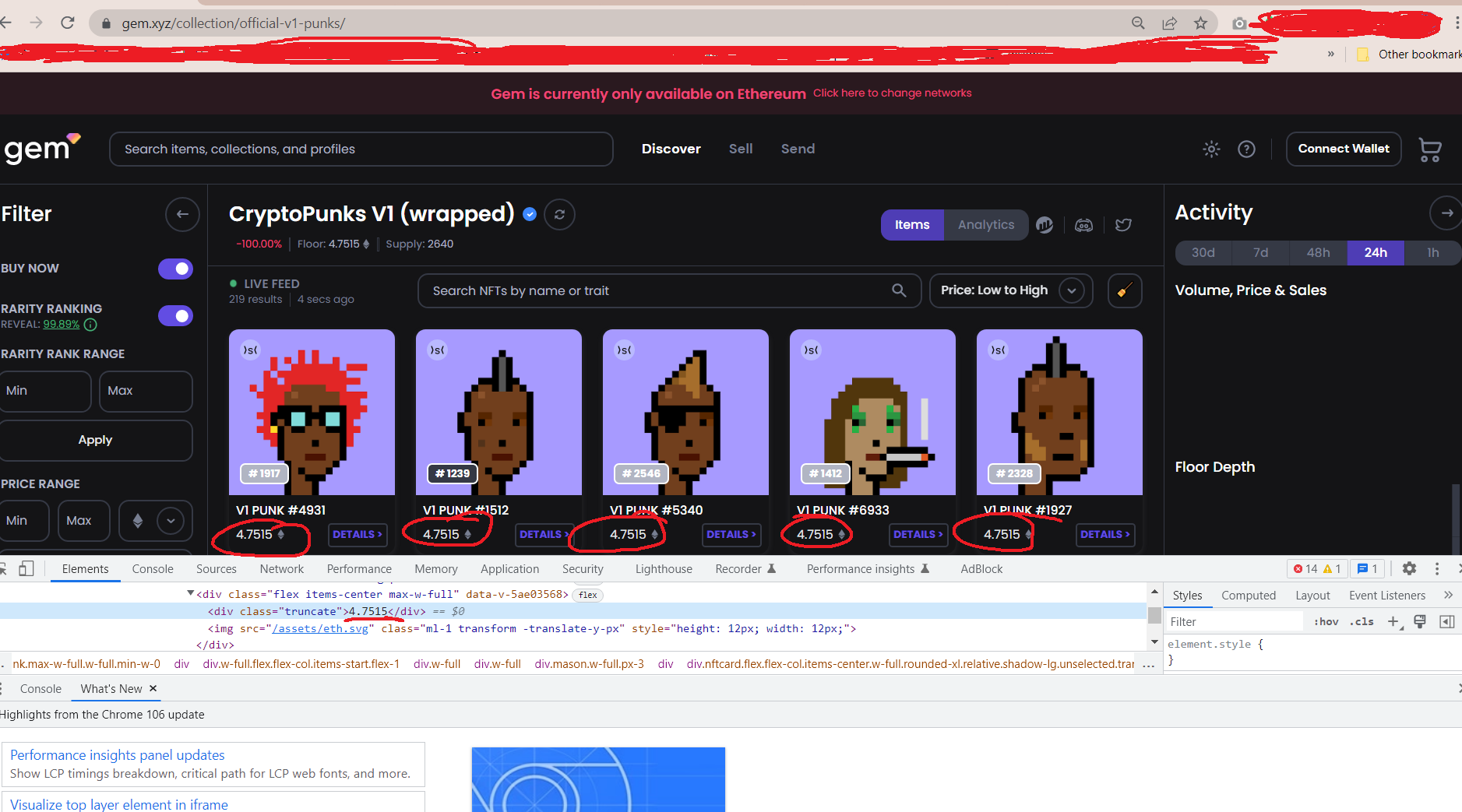
And as such I copied the Xpath and CSS selector as follows:
css selector - #app > div > div.inline-flex.items-between.relative.h-full.flex-col.md\:flex-row.justify-between.swap > div.flex.flex-col.justify-between.flex-shrink.max-w-full.w-full.min-w-0 > div:nth-child(1) > div > div:nth-child(2) > div > div.mason.w-full.px-3 > div:nth-child(1) > div:nth-child(1) > div.p-2.w-full > div.flex.justify-between.items-center.text-sm.text-gray-600.dark\:text-gray-300.h-7 > div > div > div > div
Xpath - //*[@id="app"]/div/div[3]/div[2]/div[1]/div/div[2]/div/div[3]/div[1]/div[1]/div[4]/div[2]/div/div/div/div
Full Xpath - /html/body/div[1]/div/div[3]/div[2]/div[1]/div/div[2]/div/div[3]/div[1]/div[1]/div[4]/div[2]/div/div/div/div
And my code
import sys
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Control panel
headless_webdriver_switch = True
print_switch = True
sole_print_switch = False
if sole_print_switch:
print_switch = False
# Main
main_url = 'https://www.gem.xyz/collection/official-v1-punks/'
current_path = os.getcwd()
driver_path = os.path.join(current_path, 'chrome_driver', 'chromedriver.exe')
options = Options()
if headless_webdriver_switch:
options.headless = True
options.add_argument('--window-size=1920,1200')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--incognito')
driver = webdriver.Chrome(options=options, executable_path=driver_path)
driver.get(main_url)
if print_switch:
print(driver.page_source)
# Search elements
# Using CSS selector
curr_css_selector = '#app > div > div.inline-flex.items-between.relative.h-full.flex-col.md\:flex-row.justify-between.swap > div.flex.flex-col.justify-between.flex-shrink.max-w-full.w-full.min-w-0 > div:nth-child(1) > div > div:nth-child(2) > div > div.mason.w-full.px-3 > div:nth-child(1) > div:nth-child(1) > div.p-2.w-full > div.flex.justify-between.items-center.text-sm.text-gray-600.dark\:text-gray-300.h-7 > div > div > div > div'
elements_by_css_selector = driver.find_elements_by_css_selector(curr_css_selector)
print(elements_by_css_selector)
# Using XPATH
curr_xpath = '//*[@id="app"]/div/div[3]/div[2]/div[1]/div/div[2]/div/div[3]/div[1]/div[1]/div[4]/div[2]/div/div/div/div'
curr_full_xpath = '/html/body/div[1]/div/div[3]/div[2]/div[1]/div/div[2]/div/div[3]/div[1]/div[1]/div[4]/div[2]/div/div/div/div'
elements_by_xpath = driver.find_element_by_xpath(curr_xpath)
print(elements_by_xpath)
driver.quit()
print(driver.page_source) results (not shown due to size) does NOT seem to contain the prices.
The print(elements_by_css_selector) resulted in empty list []
And print(elements_by_xpath) resulted in the following error:
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//*[@id="app"]/div/div[3]/div[2]/div[1]/div/div[2]/div/div[3]/div[1]/div[1]/div[4]/div[2]/div/div/div/div"}
(Session info: headless chrome=106.0.5249.91)
Why is the content not shown in driver.page_source, and how can I extract it?
CodePudding user response:
To find the price:
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Control panel
headless_webdriver_switch = True
print_switch = True
sole_print_switch = False
if sole_print_switch:
print_switch = False
# Main
main_url = 'https://www.gem.xyz/collection/official-v1-punks/'
current_path = os.getcwd()
driver_path = os.path.join(current_path, 'chrome_driver', 'chromedriver.exe')
options = Options()
if headless_webdriver_switch:
options.headless = True
options.add_argument('--window-size=1920,1200')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--incognito')
driver = webdriver.Chrome(options=options, executable_path=driver_path)
driver.get(main_url)
if print_switch:
print(driver.page_source)
row = 1
column = 1
price = driver.find_element_by_xpath("/html/body/div/div/div[2]/div[2]/div[1]/div/div[2]/div/div[3]/div[" str(column) "]/div[" str(row) "]/div[4]/div[2]/div/div/div/div").text
driver.quit()
For example, to find the price in the 2nd row and 3rd column, you would set row to 2 and column to 3. Hope this helps!
CodePudding user response:
The main hindrance here is html element selection. You can see in chrome devtools that the element locator select the element but the same price tag and its atttr also select others text node value. So I use selenium with bs4 the reason is bs4 is super powerful to grab the html contents.
Working code as an example:
import pandas as pd
from selenium import webdriver
import time
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
webdriver_service = Service("./chromedriver") #Your chromedriver path
driver = webdriver.Chrome(service=webdriver_service)
url ='https://www.gem.xyz/collection/official-v1-punks/'
driver.get(url)
driver.maximize_window()
time.sleep(10)
soup = BeautifulSoup(driver.page_source,"html.parser")
e=[]
for card in soup.select('div[]'):
p = card.select_one('div[] div > div > div > div > div')
p= p.get_text(strip=True) if p else None
d={
"price":p
}
e.append(d)
df= pd.DataFrame(e)
print(df)
Output:
price
0 4.7515
1 4.7515
2 4.7515
3 4.7705
4 4.7705
5 4.7705
6 4.7705
7 4.7705
8 4.7705
9 4.7705
10 4.7515
11 4.7515
12 4.7515
13 4.7705
14 4.7705
15 4.7705
16 4.7705
17 4.7705
18 4.7705
19 4.7705
20 4.7515
21 4.7515
22 4.7705
23 4.7705
24 4.7705
25 4.7705
26 4.7705
27 4.7705
28 4.7705
29 4.7705
CodePudding user response:
If I understood your question correctly, the following is how you can solve it using the requests module:
import requests
from pprint import pprint
link = 'https://gem-api-v2-2.herokuapp.com/assets'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'x-api-key': 'rLnNH1tdrT09EQjGsjrSS7V3uGonfZLW',
'Origin': 'https://www.gem.xyz'
}
params = {"filters":{"traits":{},"traitsRange":{},"slug":"official-v1-punks","rankRange":{},"price":{}},"sort":{"currentEthPrice":"asc"},"fields":{"id":1,"name":1,"address":1,"collectionName":1,"collectionSymbol":1,"externalLink":1,"imageUrl":1,"smallImageUrl":1,"animationUrl":1,"openRarityRank":1,"standard":1,"perItemEthPrice":1,"market":1,"pendingTrxs":1,"currentBasePrice":1,"paymentToken":1,"marketUrl":1,"marketplace":1,"tokenId":1,"priceInfo":1,"tokenReserves":1,"ethReserves":1,"sudoPoolAddress":1,"sellOrders":1,"startingPrice":1,"rarityScore":1},"offset":0,"limit":30,"markets":[],"status":["buy_now"]}
def get_price(item):
price = str(float(item) / 1000000000000000000)[:6]
return price
with requests.Session() as s:
s.headers.update(headers)
res = s.post(link,json=params)
for item in res.json()['data']:
item_name = item['name']
item_price = get_price(item['priceInfo']['price'])
print((item_name,item_price))
Output:
('V1 PUNK #4931', '4.7515')
('V1 PUNK #1512', '4.7515')
('V1 PUNK #5340', '4.7515')
('V1 PUNK #6933', '4.7515')
('V1 PUNK #1927', '4.7515')
('V1 PUNK #8154', '4.7515')
('V1 PUNK #4972', '4.7515')
('V1 PUNK #5947', '4.7515')
('V1 PUNK #1306', '4.7705')
('V1 PUNK #1466', '4.7705')
('V1 PUNK #1778', '4.7705')
('V1 PUNK #2043', '4.7705')
('V1 PUNK #7957', '4.7705')
('V1 PUNK #9419', '4.7705')
('V1 PUNK #3418', '4.7705')
('V1 PUNK #6517', '4.7705')
('V1 PUNK #6825', '4.7705')
('V1 PUNK #8798', '4.7705')
('V1 PUNK #1277', '4.7705')
('V1 PUNK #2037', '4.7705')
('V1 PUNK #2999', '4.7705')
('V1 PUNK #2972', '4.7705')
('V1 PUNK #2959', '4.7705')
('V1 PUNK #2970', '4.7705')
('V1 PUNK #2772', '4.7705')
('V1 PUNK #3357', '4.7705')
('V1 PUNK #3312', '4.7705')
('V1 PUNK #3219', '4.7705')
('V1 PUNK #3261', '4.7705')
('V1 PUNK #3286', '4.7705')