Currently have the following where I find the UPPERCASE: and change it BOLD and leave it as UPPERCASE:
What I would prefer is to have it change to BOLD Proper Case:.
17
00:00:37,689 --> 00:00:39,863
BOTH: ♪ Put on a happy, happy, happy ♪
20
00:00:43,260 --> 00:00:44,651
MR. OWENS: Hello!
29
00:01:05,717 --> 00:01:07,413
NURSE #1: You want me to inject him?
56
00:02:29,061 --> 00:02:30,960
MALE NARRATOR: Two Sockatoos, one bullet...
844
00:46:57,418 --> 00:46:59,462
TOGETHER: Seriously?
Here is what I currently use to find and replace in modifing it BOLD:
Find 1U: ([A-Z0-9][A-Z0-9. -',-:&@#] )(?=:\B)
Replace 1: \<b\>$1\<\/b\>
Then I use this to change the 1st word to proper case, but can't figure out how to make it work when SPACES are involved.
Step #1 Make it lowercase after the above <b>SANDRA</b>
---------------------------------------------------------------------
Find: <b>([A-Z0-9][A-Z0-9. -',-:&@#] )</b>
Replace: <b>\L\1</b>
Step #2 Now change it to Proper Case <b>sandra</b>
---------------------------------------------------------------------
Find: <b>([a-z])
Replace: <b>\U$1
OK, stop laughing, it's the best I could come up with. Still a n00b with regex/notepad
Be nice if nice if I could this in ONE step.
Thanks in Advance
CodePudding user response:
You cannot pack the three steps into one, but you can do it with two steps. The first step is your first step, if it works as expected you can keep using this approach (replacing ([A-Z0-9][A-Z0-9. -',-:&@#] )(?=:\B) with <b>$1</b> (please do not escape angle brackets)).
The next step is turning the first word char to an uppercase char, and the rest to the lowercase chars.
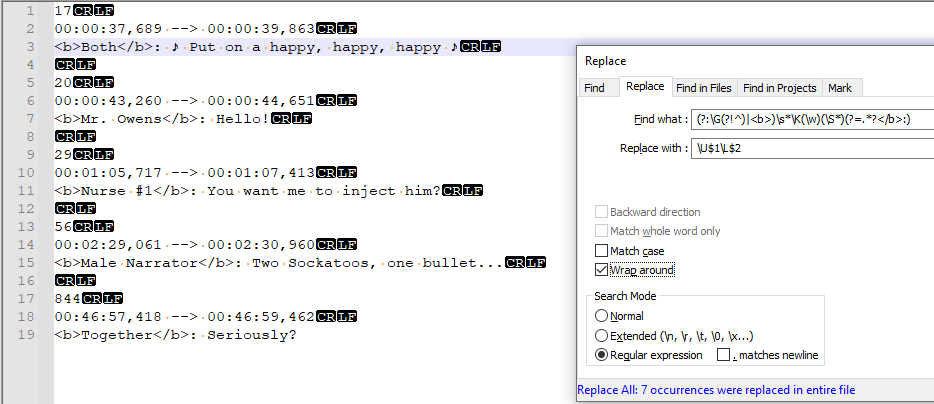
Find What: (?:\G(?!^)|<b>)\s*\K(\w)(\S*)(?=.*?</b>:)
Replace With: \U$1\L$2
Details:
(?:\G(?!^)|<b>)-<b>or the end of the preceding match\s*- zero or more whitespaces\K- omit the matched text(\w)- Group 1: a word char(\S*)- Group 2: any zero or more chars other than whitespace(?=.*?</b>:)- a positive lookahead that matches a location that is immediately followed with any zero or more chars other than line break chars as few as possible and then</b>:.
See the demo and settings below: