I am trying to load a files from s3 to Athena to perform a query operation. But all the column values are getting added to the first column.
I have file in the following format:
id,user_id,personal_id,created_at,updated_at,active
34,34,43,31:28.4,27:07.9,TRUE
This is the output I get:
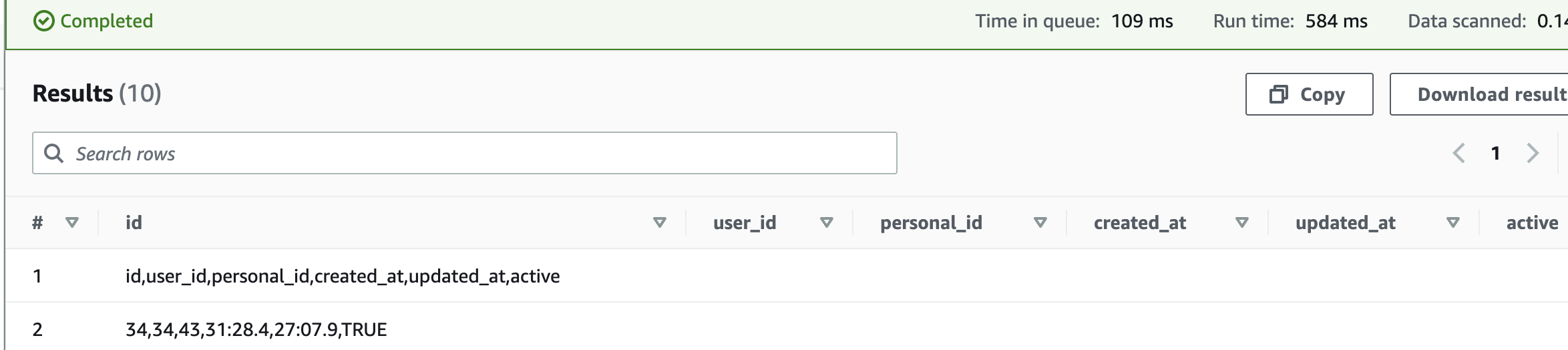
Table creation query:
CREATE EXTERNAL TABLE `testing`(
`id` string,
`user_id` string,
`personal_id` string,
`created_at` string,
`updated_at` string,
`active` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://testing2fa/'
TBLPROPERTIES (
'transient_lastDdlTime'='1665356861')
Please can someone tell me where am I going wrong?
CodePudding user response:
You should add skip.header.line.count to your table properties to skip the first row. As you have defined all columns as string data type Athena was unable to differentiate between header and first row.
DDL with property added:
CREATE EXTERNAL TABLE `testing`(
`id` string,
`user_id` string,
`personal_id` string,
`created_at` string,
`updated_at` string,
`active` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://testing2fa/'
TBLPROPERTIES ('skip.header.line.count'='1')
CodePudding user response:
The Serde needs some parameter to recognize CSV files, such as:
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
See: LazySimpleSerDe for CSV, TSV, and custom-delimited files - Amazon Athena
An alternative method is to use AWS Glue to create the tables for you. In the AWS Glue console, you can create a Crawler and point it to your data. When you run the crawler, it will automatically create a table definition in Amazon Athena that matches the supplied data files.