I have to load a txt file into pandas that look like this:
20221001T000022649 sdff002 0011 $LNKD word1 word2 word3
20221001T000022733 SDSD002 0011 SD8 word1 word2 word3 word4
20221001T000022758 SDSD002 0011 NLP word1 word2 word3 word1word2 word3
20221001T000022808 SDSD002 0011 JKT word1 word2 word3 word1 word2
20221001T000022823 SDSD002 0011 SD8 word1 word2 word3
I was thinking about:
mydf = pd.read_csv("test_query.txt", sep = " ")
Assuming that the words are separated by one space and the other records are separated by more than one space. the last words word1 word2 etc should all together go in one column. This does not work because gives several empty columns since the spaces are random.
What is for sure is that there is no space in the first 4 records i.e. 20221001T000022649 sdff002 0011 $LNKD
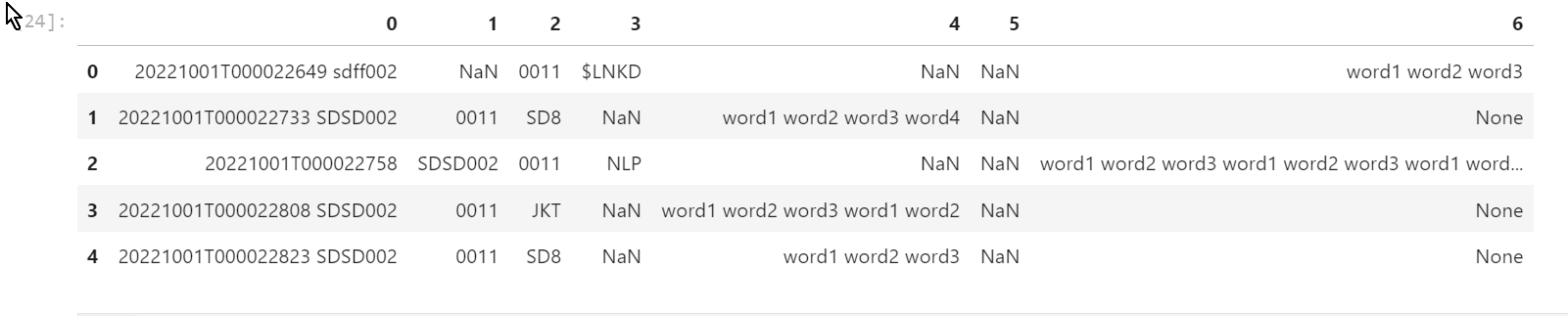
So how would you go about this problem? Parsing one line by line?
thanks
CodePudding user response:
To be honest, I'd make sure you use the pd.read_csv function for reading csv files. So what you could do is either write a program that transforms you .txt file into a csv and then run it again or start from csv.
Hope this helps you out.
CodePudding user response:
you can use regex as seperator
pd.read_csv("test_query.txt", sep = '\s ')
CodePudding user response:
Edit
>>> import re
>>> import pandas as pd
>>>
>>> rows = []
>>> for line in data.split("\n"):
>>> chunks = re.split(' ', line)
>>> rows.append(chunks[:4] [','.join(chunks[4:])])
>>>
>>> df = pd.DataFrame(rows)
>>>
>>> print(df)
0 1 2 3 4
0 20221001T000022649 sdff002 0011 $LNKD word1,word2,word3
1 20221001T000022733 SDSD002 0011 SD8 word1,word2,word3,word4
2 20221001T000022758 SDSD002 0011 NLP word1,word2,word3,word1word2,word3
3 20221001T000022808 SDSD002 0011 JKT word1,word2,word3,word1,word2,
4 20221001T000022823 SDSD002 0011 SD8 word1,word2,word3
CodePudding user response:
Another possible solution is to use engine='python' to force using at least 2 spaces as separator (sep='\s{2,}'):
df = pd.read_csv("test_query.txt", sep='\s{2,}', engine='python', header=None)
Output:
0 1 2 3 4
0 20221001T000022649 sdff002 11 $LNKD word1 word2 word3
1 20221001T000022733 SDSD002 11 SD8 word1 word2 word3 word4
2 20221001T000022758 SDSD002 11 NLP word1 word2 word3 word1word2 word3
3 20221001T000022808 SDSD002 11 JKT word1 word2 word3 word1 word2
4 20221001T000022823 SDSD002 11 SD8 word1 word2 word3