import pandas as pd
data = [10]
booklines = pd.DataFrame(data,columns=['Nums'])
matches = {'Fullname':['Sasel - Dassendorf'],'HomeTeam':['Sasel'],'AwayTeam':['Dassendorf']}
matches_df = pd.DataFrame(matches)
Is there a way I can replicate the number of rows in matches_df based on the row value 10 which is present in booklines.
The end result is the matches df replicated ten times like this. I am looking for a programatic way of doing this instead of manually adding in the ten like so.
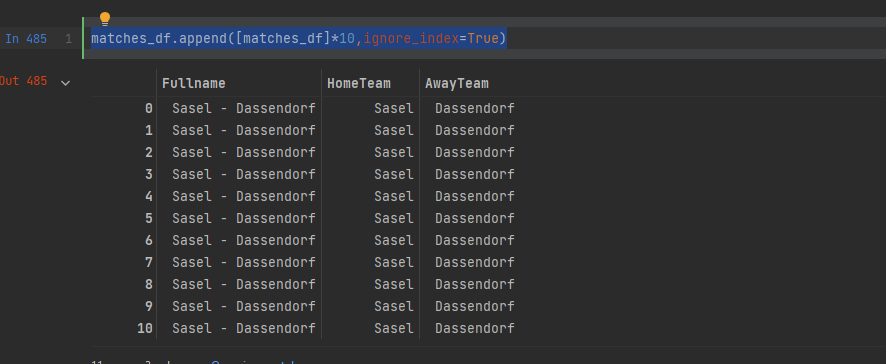
matches_df.append([matches_df]*10,ignore_index=True)
CodePudding user response:
Use:
val = booklines['Nums'].iat[0]
matches = {'Fullname':['Sasel - Dassendorf']*val,
'HomeTeam':['Sasel']*val,
'AwayTeam':['Dassendorf']*val}
matches_df = pd.DataFrame(matches)
Or:
matches = {'Fullname':['Sasel - Dassendorf'],'HomeTeam':['Sasel'],'AwayTeam':['Dassendorf']}
matches_df = pd.DataFrame(matches).reindex(range(val), method='ffill')
print (matches_df)
Fullname HomeTeam AwayTeam
0 Sasel - Dassendorf Sasel Dassendorf
1 Sasel - Dassendorf Sasel Dassendorf
2 Sasel - Dassendorf Sasel Dassendorf
3 Sasel - Dassendorf Sasel Dassendorf
4 Sasel - Dassendorf Sasel Dassendorf
5 Sasel - Dassendorf Sasel Dassendorf
6 Sasel - Dassendorf Sasel Dassendorf
7 Sasel - Dassendorf Sasel Dassendorf
8 Sasel - Dassendorf Sasel Dassendorf
9 Sasel - Dassendorf Sasel Dassendorf
If same number of rows in both DataFrames and need use Nums column for replicate use Index.repeat with DataFrame.loc:
data = [10, 7]
booklines = pd.DataFrame(data,columns=['Nums'])
print (booklines)
Nums
0 10
1 7
matches = {'Fullname':['Sasel - Dassendorf', 'Sasel - Dassendorf'],
'HomeTeam':['Sasel', 'Dassendorf'],
'AwayTeam':['Dassendorf', 'Sasel']}
matches_df = pd.DataFrame(matches)
print (matches_df)
Fullname HomeTeam AwayTeam
0 Sasel - Dassendorf Sasel Dassendorf
1 Sasel - Dassendorf Dassendorf Sasel
df = matches_df.loc[matches_df.index.repeat(booklines['Nums'])]
print (df)
Fullname HomeTeam AwayTeam
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
0 Sasel - Dassendorf Sasel Dassendorf
1 Sasel - Dassendorf Dassendorf Sasel
1 Sasel - Dassendorf Dassendorf Sasel
1 Sasel - Dassendorf Dassendorf Sasel
1 Sasel - Dassendorf Dassendorf Sasel
1 Sasel - Dassendorf Dassendorf Sasel
1 Sasel - Dassendorf Dassendorf Sasel
1 Sasel - Dassendorf Dassendorf Sasel
Last for default index use:
df = df.reset_index(drop=True)