I am trying to Select a subset of a dataframe where following conditions are satisfied:
- for same category keep only the row with highest note,
- if category=na keep the row
Here's my dataframe example :
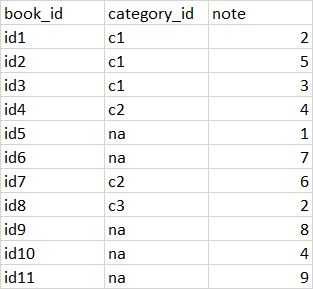
The expected result:
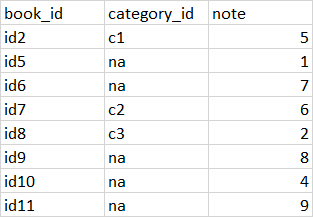
What is the efficient way to do it? Thank you
CodePudding user response:
Use DataFrame.sort_values with mask chained DataFrame.duplicated with bitwise OR for missing rows by same column:
df1 = df.sort_values(['category_id','note'])
df1 = df1[~df1.duplicated(['category_id'], keep='last') |
df1['category_id'].isna()].sort_index()
print (df1)
book_id category_id note
1 id2 c1 5
4 id5 NaN 1
5 id6 NaN 7
6 id7 c2 6
7 id8 c3 2
8 id9 NaN 8
9 id10 NaN 4
10 id11 NaN 9
Or use Series.fillna with range (necessary non integers in category_id) and then use DataFrameGroupBy.idxmax:
s = df['category_id'].fillna(pd.Series(range(len(df)), index=df.index))
df1 = df.loc[df.groupby(s)['note'].idxmax()].sort_index()
print (df1)
book_id category_id note
1 id2 c1 5
4 id5 NaN 1
5 id6 NaN 7
6 id7 c2 6
7 id8 c3 2
8 id9 NaN 8
9 id10 NaN 4
10 id11 NaN 9
CodePudding user response:
Sorting has a O(n*logn) complexity, so better use a linear time approach when you can.
You can use boolean indexing with two masks:
# is the row a NA?
m1 = df['category_id'].isna()
# is the row the max value for a non NA?
m2 = df.index.isin(df.groupby('category_id')['note'].idxmax())
# or if you want to keep all max rows if several
# m2 = df['note'].eq(df.groupby('category_id')['note'].transform('max'))
# keep if any condition is met
out = df.loc[m1|m2]
output:
book_id category_id note
1 id2 c1 5
4 id5 NaN 1
5 id6 NaN 7
6 id7 c2 6
7 id8 c3 2
8 id9 NaN 8
9 id10 NaN 4
10 id11 NaN 9
how does it work?
Here are the intermediates for the boolean masks, ultimately only the rows with True in the last mask are kept:
book_id category_id note is na? is max? is either?
0 id1 c1 2 False False False
1 id2 c1 5 False True True
2 id3 c1 3 False False False
3 id4 c2 4 False False False
4 id5 NaN 1 True False True
5 id6 NaN 7 True False True
6 id7 c2 6 False True True
7 id8 c3 2 False True True
8 id9 NaN 8 True False True
9 id10 NaN 4 True False True
10 id11 NaN 9 True False True