I have a dataframe like this
#Test dataframe
import pandas as pd
import numpy as np
#Build df
titles = {'Title': ['title1', 'cat', 'dog']}
references = {'References': [['donkey','chicken'],['title1','dog'],['bird','snake']]}
df = pd.DataFrame({'Title': ['title1', 'cat', 'dog'], 'References': [['donkey','chicken'],['title1','dog'],['bird','snake']]})
#Insert IDs for UNIQUE titles
title_ids = {'IDs':list(np.arange(0,len(df)) 1)}
df['IDs'] = list(np.arange(0,len(df)) 1)
df = df[['Title','IDs','References']]
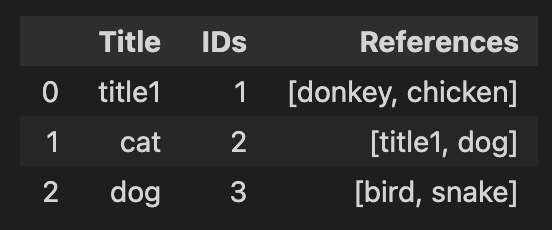
and I want to generate IDs for the references column that looks like the data frame below. If there is a matching between the strings, assign the same ID as in the IDs column and if not, assign a new unique ID.

My first attempt is using the function
#Matching function
def string_match(string1,string2):
if string1 == string2:
a = 1
else:
a = 0
return a
and to loop over each string/title combination but this gets tricky with multiple for loops and if statements. Is there a better way I can do this that is more pythonic?
CodePudding user response:
# Explode to one reference per row
references = df["References"].explode()
# Combine existing titles with new title from References
titles = pd.concat([df["Title"], references]).unique()
# Assign each title an index number
mappings = {t: i 1 for i, t in enumerate(titles)}
# Map the reference to the index number and convert to list
df["RefIDs"] = references.map(mappings).groupby(level=0).apply(list)
CodePudding user response:
Let us try with factorize
s = df['References'].explode()
s[:] = pd.concat([df['Title'],s]).factorize()[0][len(df['Title']):]
df['new'] = (s 1).groupby(level=0).agg(list)
Out[237]:
0 [4, 5]
1 [1, 3]
2 [6, 7]
Name: References, dtype: object