I am trying to upsample a pandas datetime-indexed dataframe, so that resulting data is equally divided over the new entries.
For instance, let's say I have a dataframe which stores a cost each month, and I want to get a dataframe which summarizes the equivalent costs per day for each month:
df = (pd.DataFrame([[pd.to_datetime('2023-01-01'), 31],
[pd.to_datetime('2023-02-01'), 14]],
columns=['time', 'cost']
)
.set_index("time")
)
Daily costs are 1$ (or whatever currency you like) in January, and 0.5$ in February. My goal in picture:
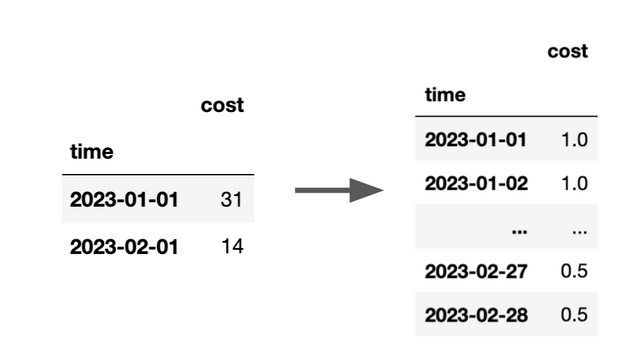
After a lot of struggle, I managed to obtain the next code snippet which seems to do what I want:
# add a value to perform a correct resampling
df.loc[df.index.max() relativedelta(months=1)] = 0
# forward-fill over the right scale
# then divide each entry per the number of rows in the month
df = (df
.resample('1d')
.ffill()
.iloc[:-1]
.groupby(lambda x: datetime(x.year, x.month, 1))
.transform(lambda x: (x / x.count()))
)
However, this is not entirely ok:
- using
transformforces me to have dataframes with a single column ; - I need to hardcode my original frequency several times in different formats (while adding an extra value at the end of the dataframe, and in the groupby), making a function design hard ;
- It only works with evenly-spaced datetime index (even if it's ok in my case) ;
- it remains complex.
Does anyone have a suggestion to improve that code snippet ?
CodePudding user response:
What if we took df's month indices and expanded them into days range, while dividing df's values by a number those days and assigning to each day, all by list comprehensions (edit: for equally distributed values per day):
import pandas as pd
# initial DataFrame
df = (pd.DataFrame([[pd.to_datetime('2023-01-01'), 31],
[pd.to_datetime('2023-02-01'), 14]],
columns=['time', 'cost']
).set_index("time"))
# reformat to months
df.index = df.index.strftime('%m-%Y')
df1 = pd.concat( # concatenate the resulted DataFrames into one
[pd.DataFrame( # make a DataFrame from a row in df
[v / pd.Period(i).days_in_month # each month's value divided by n of days in a month
for d in range(pd.Period(i).days_in_month)], # repeated for as many times as there are days
index=pd.date_range(start=i, periods=pd.Period(i).days_in_month, freq='D')) # days range
for i, v in df.iterrows()]) # for each df's index and value
df1
Output:
cost
2023-01-01 1.0
2023-01-02 1.0
2023-01-03 1.0
2023-01-04 1.0
2023-01-05 1.0
2023-01-06 1.0
2023-01-07 1.0
2023-01-08 1.0
2023-01-09 1.0
2023-01-10 1.0
2023-01-11 1.0
... ...
2023-02-13 0.5
2023-02-14 0.5
2023-02-15 0.5
2023-02-16 0.5
2023-02-17 0.5
2023-02-18 0.5
2023-02-19 0.5
2023-02-20 0.5
2023-02-21 0.5
2023-02-22 0.5
2023-02-23 0.5
2023-02-24 0.5
2023-02-25 0.5
2023-02-26 0.5
2023-02-27 0.5
2023-02-28 0.5
What could be done to avoid uniform distribution of daily costs and for the cases with multiple columns? Here's an extended df:
# additional columns and a row
df = (pd.DataFrame([[pd.to_datetime('2023-01-01'), 31, 62, 23],
[pd.to_datetime('2023-02-01'), 14, 28, 51],
[pd.to_datetime('2023-03-01'), 16, 33, 21]],
columns=['time', 'cost1', 'cost2', 'cost3']
).set_index("time"))
# reformat to months
df.index = df.index.strftime('%m-%Y')
df
Output:
cost1 cost2 cost3
time
01-2023 31 62 23
02-2023 14 28 51
03-2023 16 33 21
Here's what I came up for the cases where monthly costs may be upsampled by randomized daily costs, inspired by this question. This solution is scalable to the number of columns and rows:
df1 = pd.concat( # concatenate the resulted DataFrames into one
[pd.DataFrame( # make a DataFrame from a row in df
# here we make a Series with random Dirichlet distributed numbers
# with length of a month and a column's value as the sum
[pd.Series((np.random.dirichlet(np.ones(pd.Period(i).days_in_month), size=1)*v
).flatten()) # the product is an ndarray that needs flattening
for v in row], # for every column value in a row
# index renamed as columns because of the created DataFrame's shape
index=df.columns
# transpose and set the proper index
).T.set_index(
pd.date_range(start=i,
periods=pd.Period(i).days_in_month,
freq='D'))
for i, row in df.iterrows()]) # iterate over every row
Output:
cost1 cost2 cost3
2023-01-01 1.703177 1.444117 0.160151
2023-01-02 0.920706 3.664460 0.823405
2023-01-03 1.210426 1.194963 0.294093
2023-01-04 0.214737 1.286273 0.923881
2023-01-05 1.264553 0.380062 0.062829
... ... ... ...
2023-03-27 0.124092 0.615885 0.251369
2023-03-28 0.520578 1.505830 1.632373
2023-03-29 0.245154 3.094078 0.308173
2023-03-30 0.530927 0.406665 1.149860
2023-03-31 0.276992 1.115308 0.432090
90 rows × 3 columns
To assert the monthly sum:
df1.groupby(pd.Grouper(freq='M')).agg('sum')
Output:
cost1 cost2 cost3
2023-01-31 31.0 62.0 23.0
2023-02-28 14.0 28.0 51.0
2023-03-31 16.0 33.0 21.0