I have some time series data in a pandas dataframe that I can visualise as follows:
import pandas as pd
d = {'end_time': [datetime.datetime(2020, 3, 17, 0, 0), datetime.datetime(2020, 3, 17, 0, 5), datetime.datetime(2020, 3, 17, 0, 10), datetime.datetime(2020, 3, 17, 0, 15), datetime.datetime(2020, 3, 17, 0, 20), datetime.datetime(2020, 3, 17, 0, 25), datetime.datetime(2020, 3, 17, 0, 30), datetime.datetime(2020, 3, 17, 0, 35), datetime.datetime(2020, 3, 17, 0, 40), datetime.datetime(2020, 3, 17, 0, 45), datetime.datetime(2020, 3, 17, 0, 50), datetime.datetime(2020, 3, 17, 0, 55)], "measurement": [2000, 1500, 800, 900, 400, 4000, 300, 900, 1000, 1250, 1100, 1300], "reliability": [99, 81, 84, 85, 99, 86, 96, 97, 98, 99, 98, 97]}
# select some relevant columns
subset_df = pd.DataFrame.from_dict(d)
# plot measurements over time
subset_df.plot('end_time', 'measurement')
Now the reliabilitycolumn is a number between 0 and 100. What I want to do is highlight areas where this reliability score is below 95. So something where I can overlay a transparent box around those areas to visually highlight where the measurements may not be very reliable.
CodePudding user response:
Considering this random dataframe, where
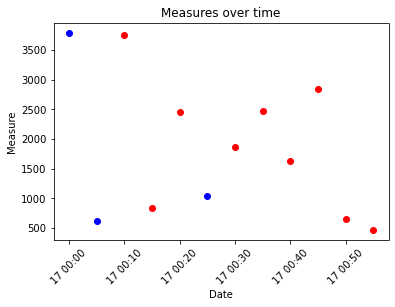
end_time: dates starting from2020-03-17 00:00:00to2020-03-17 00:55:00with a5minutes intervalmeasurement: random integers between300and4000reliability: random integers between0and100import pandas as pd import numpy as np df = pd.DataFrame({'end_time': pd.date_range(start='2020-03-17 00:00:00', end='2020-03-17 00:55:00', freq='5min'), 'measurement': np.random.randint(300, 4000, size=12), 'reliability': np.random.randint(0, 100, size=12)}) [Out]: end_time measurement reliability 0 2020-03-17 00:00:00 3792 95 1 2020-03-17 00:05:00 623 95 2 2020-03-17 00:10:00 3759 22 3 2020-03-17 00:15:00 842 81 4 2020-03-17 00:20:00 2458 89 5 2020-03-17 00:25:00 1031 98 6 2020-03-17 00:30:00 1858 61 7 2020-03-17 00:35:00 2473 90 8 2020-03-17 00:40:00 1636 93 9 2020-03-17 00:45:00 2846 57 10 2020-03-17 00:50:00 645 90 11 2020-03-17 00:55:00 460 42
If the goal is to plot all measures with a reliability lower than 95 in red and the rest in blue, let us first create a few variables that will be useful:
measurementwith areliabilitylower than95:measures = df[df.reliability < 95].measurementend_timeof themeasurementwith areliabilitylower than95:dates = df[df.reliability < 95].end_timemeasurementwith areliabilityhigher than 95:measures2 = df[df.reliability >= 95].measurementend_timeof themeasurementwith areliabilityhigher than95:dates2 = df[df.reliability >= 95].end_time
Now let us create the plot
import matplotlib.pyplot as plt
# Create the plot:
plt.plot(dates, measures, 'ro', dates2, measures2, 'bo')
# Set the title:
plt.title('Measures over time')
# Set the x label:
plt.xlabel('Date')
# Set the y label:
plt.ylabel('Measure')
# Set the x ticks:
plt.xticks(rotation=45)
# Show the plot:
plt.show()
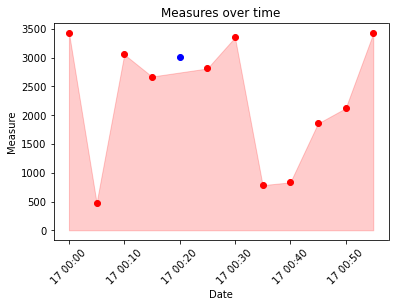
As per OP's new requirement (use fill_between so that I can paint a transparent box from the x-axes to the top of y-axes), before plt.show() one can use the following
plt.fill_between(dates, 0, measures, color='red', alpha=0.2)
With a different dataframe it would look like this