I have the following case: A data table of shipments (dfSysTemp) with fields: AWB, Origin, Route, HubGW.

A character vector of standard Hub 3-letter acronyms.
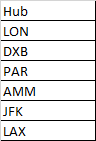
The Route consists of multiple 3-letter entities separated by a hyphen (-). I need to update the HubGW field with the first Entity that exists in the list of Hubs as shown in the table.
What I have performed:
I used 3 functions and a For loop with sapply as shown in the code. This succeeded in getting the expected HubGW but it took around 8 minutes of processing time on 1.2M shipment records.
# Get list of standard Hubs from Access DB
vHubs <- sqlFetch(dbMaster,"Hubs") %>%
as.data.frame() %>%
pull(Hub)
# create the Hubs pattern
HubsPattern=vHubs[1]
for (h in 2:length(vHubs)){
HubsPattern=paste0(HubsPattern,"|",vHubs[h])
}
# Define a function to split the Route into Entities
SplitRoute <- function(route){
str_split(route,"-")}`
# Define a function that takes in the split Route and return the first
# standard Hub in the Route
FetchHub1 <- function(z) {sapply(SplitRoute(z),grep,pattern=HubsPattern,value=TRUE) %>%
unlist() %>% .[1]}
# Apply the Fetch Hub1 function to the System Temp data to assign
# the first hub for each shipment
for (i in 1:dfSysTemp[,.N]){
dfSysTemp[i,`:=`(HubGW=FetchHub1(Route))]
}
I had to loop over all shipments using For loop since using sapply alone did not allocate the correct HubGW for the shipments. It rather allocated the first HubGW value it found to the entire list of shipments regardless of the Route.
I believe there is a better way to do it using the ‘apply’ functions that can cut the processing time considerably.
Any thoughts on this are highly appreciated.
Thanks.
CodePudding user response:
You can split string using strsplit and then find which elements of hub vectors are in it. If there is any take first otherwise return NA:
df <- data.frame(
Route = c("BUD-LON-DXB-RUH", "MCT-DXB-RUH", "HEL-PRG-PAR-AUH", "AMM-JFK-LAX"),
HubGW = c("LON", "DXB", "PAR", "AMM"),
stringsAsFactors = FALSE
)
hub <- c("LON", "DXB", "PAR", "AMM", "JFK", "LAX")
findFirst <- function(s, table){
lgl <- table %in% s
if(any(lgl)) table[lgl][[1]] else NA_character_
}
df$new <- vapply(strsplit(df$Route, "-"), findFirst, "character", table = hub)
using data.table:
setDT(df)[, new := vapply(strsplit(df$Route, "-"), findFirst, "character", table = hub)]
CodePudding user response:
The stringi package is specifically designed for dealing with strings, has a rich functionality, and is quite fast:
routes <- c("BUD-LON-DXB-RUH", "MCT-DXB-RUH", "HEL-PRG-PAR-AUH", "AMM-JFK-LAX")
stringi::stri_extract_first_words(routes)
#> [1] "BUD" "MCT" "HEL" "AMM"