I have a data frame column name "New" below
df = pd.DataFrame({'New' : ['emerald shines bright(ABCED ID - 1234556)', 'honey in the bread(ABCED ID - 123467890)','http/ABCED/id/234555', 'healing strenght(AxYBD ID -1234556)'],
'UI': ['AOT', 'BOT', 'LOV', 'HAP']})
Now I want to extract the various IDs for example ABCED', AxYBD, and id in the 'http' into another column.
But when I used
df['New_col'] = df['New'].str.extract(r'.*\((.*)\).*',expand=True)
I can't get it to work well as the whole parenthesis for instance (ABCED ID - 1234556) is returned. More so, the http id 234555 is not returned.
CodePudding user response:
Probably not the most elegant answer,
however, I think this does what you want it to do.
import re
df = pd.DataFrame({'New' : ['emerald shines bright(ABCED ID - 1234556)', 'honey in the bread(ABCED ID - 123467890)','http/ABCED/id/234555', 'healing strenght(AxYBD ID -1234556)'],
'UI': ['AOT', 'BOT', 'LOV', 'HAP']})
# Function to extract the values of interest
def grab_text(row):
text = re.findall(r'\(([A-Za-z] )\s|/([0-9] )', row)
if text[0][0]:
# return ABCED etc
return text[0][0]
else:
# return 234555 etc
return text[0][1]
# use the function above to populate the 'New_Col' column
df['New_Col'] = df['New'].apply(grab_text)
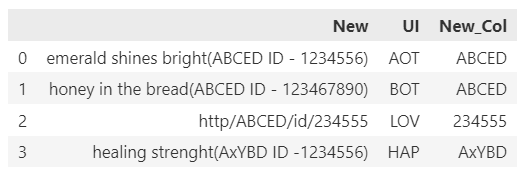
This is what df looks like now:
CodePudding user response:
r'[i,d,I,D]{2}.*?(\d.*?)\D' probably this one help
Edited: /?\(?(\w{5}) ?/?[i,d,I,D]{2} it's looks like you need letters, not digits