I read in an Excel file from an external source:
import pandas as pd
df = pd.read_excel('https://www.sharkattackfile.net/spreadsheets/GSAF5.xls')
When I call df.tail(), I see that there are 25,841 rows in this dataframe.
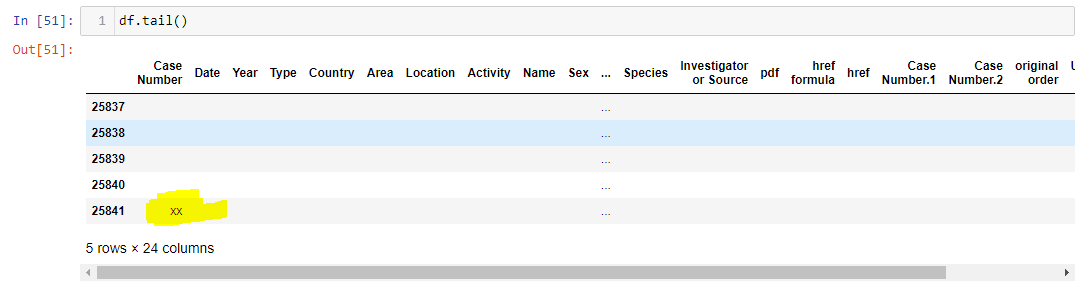
Also, notably, I see that there is a value of 'xx' in the Case Number column. This is not valid data.
But, looking at the file itself, I see that there are only 6807 rows of valid data:
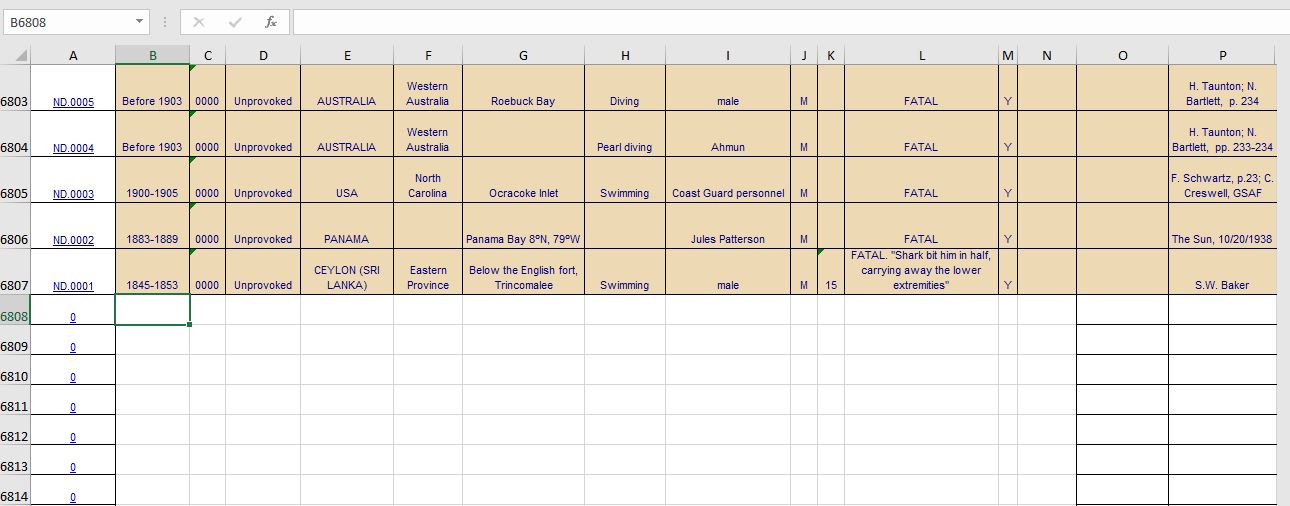
How do I get a dataframe that only has the valid data (i.e. rows 1-6807), noting that as cases are added to this file, the range would need to be dynamic?
Thanks for your help!
CodePudding user response:
You could use pandas DataFrame's replace function, then do dropna to drop every np.nan values.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.replace.html
DataFrame.replace('', np.nan)
DataFrame.replace('xx', np.nan)
DataFrame.dropna()