I have a python polars dataframe as-
df_pol = pl.DataFrame({'test_names':[['Mallesham','','Bhavik','Jagarini','Jose','Fernando'],
['','','','ABC','','XYZ']]})
I would like to get a count of elements from each list in test_names field not considering the empty values.
df_pol.with_column(pl.col('test_names').arr.lengths().alias('tot_names'))
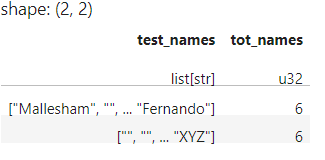
Here it is considering empty strings into count, this is why we can see 6 names in list-2. actually it has only two names.
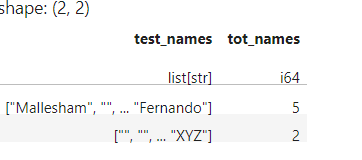
required output as:
CodePudding user response:
do you find this helpful ?
import pandas as pd
data = {'test_names': [['Mallesham', '', 'Bhavik', 'Jagarini', 'Jose', 'Fernando'],
['', '', '', 'ABC', '', 'XYZ']]}
df = pd.DataFrame(data['test_names'])
df = pd.DataFrame({'test_names': data['test_names'], 'tot_names': df[df != ''].count(axis=1)})
print(df)
CodePudding user response:
You can use arr.eval to run any polars expression on the list's elements. In an arr.eval expression, you can pl.element() to refer to the lists element and then apply an expression.
Next we simply use a filter expression to prune the values we don't need.
df = pl.DataFrame({
"test_names":[
["Mallesham","","Bhavik","Jagarini","Jose","Fernando"],
["","","","ABC","","XYZ"]
]
})
df.with_column(
pl.col("test_names").arr.eval(pl.element().filter(pl.element() != ""))
)
shape: (2, 1)
┌─────────────────────────────────────┐
│ test_names │
│ --- │
│ list[str] │
╞═════════════════════════════════════╡
│ ["Mallesham", "Bhavik", ... "Fer... │
├╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ ["ABC", "XYZ"] │
└─────────────────────────────────────┘