I have a SQL query which I am trying to convert into PySpark. In SQL query, we are joining three tables and updating a column where there's a match. The SQL query looks like this:
UPDATE [DEPARTMENT_DATA]
INNER JOIN ([COLLEGE_DATA]
INNER JOIN [STUDENT_TABLE]
ON COLLEGE_DATA.UNIQUEID = STUDENT_TABLE.PROFESSIONALID)
ON DEPARTMENT_DATA.PUBLICID = COLLEGE_DATA.COLLEGEID
SET STUDENT_TABLE.PRIVACY = "PRIVATE"
The logic I have tried:
df_STUDENT_TABLE = (
df_STUDENT_TABLE.alias('a')
.join(
df_COLLEGE_DATA('b'),
on=F.col('a.PROFESSIONALID') == F.col('b.UNIQUEID'),
how='left',
)
.join(
df_DEPARTMENT_DATA.alias('c'),
on=F.col('b.COLLEGEID') == F.col('c.PUBLICID'),
how='left',
)
.select(
*[F.col(f'a.{c}') for c in df_STUDENT_TABLE.columns],
F.when(
F.col('b.UNIQUEID').isNotNull() & F.col('c.PUBLICID').isNotNull()
F.lit('PRIVATE')
).alias('PRIVACY')
)
)
This code is adding a new column "PRIVACY", but giving null values after running.
CodePudding user response:
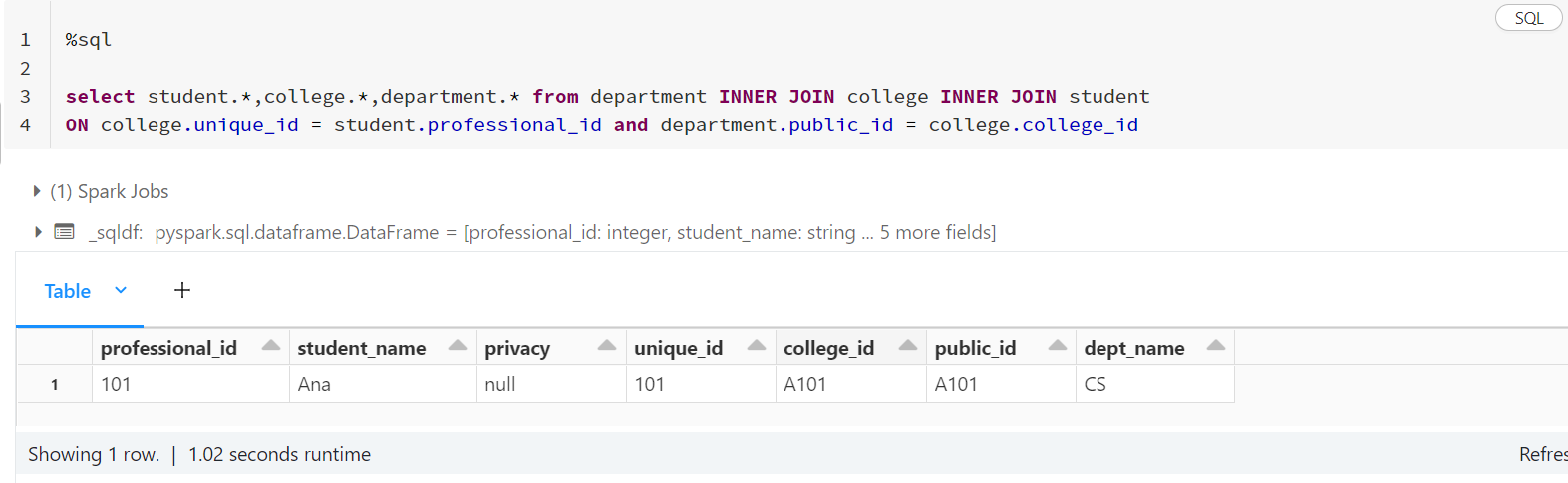
- I have taken some sample data and when I apply the join using conditions, the following is the result I get (requirement is that the following record's privacy needs to be set to
PRIVATE)
%sql
select student.*,college.*,department.* from department INNER JOIN college INNER JOIN student
ON college.unique_id = student.professional_id and department.public_id = college.college_id
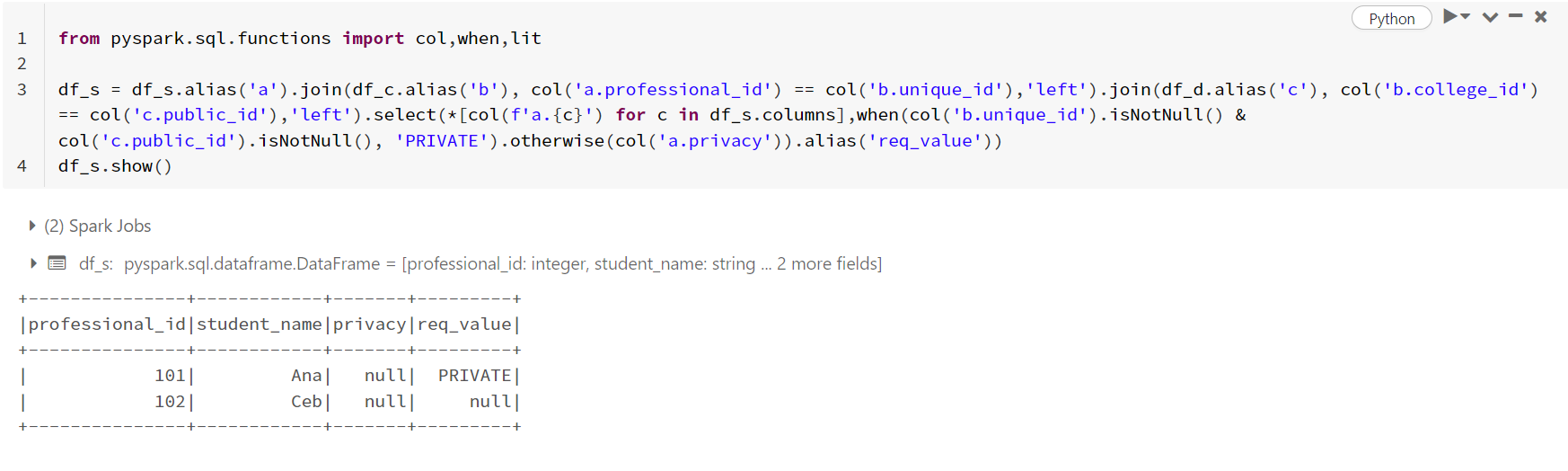
- When I used your code (same logic), I got the same output i.e., an additional column being added to the dataframe with required values and the actual
privacycolumn has nulls.
from pyspark.sql.functions import col,when,lit
df_s = df_s.alias('a').join(df_c.alias('b'), col('a.professional_id') == col('b.unique_id'),'left').join(df_d.alias('c'), col('b.college_id') == col('c.public_id'),'left').select(*[col(f'a.{c}') for c in df_s.columns],when(col('b.unique_id').isNotNull() & col('c.public_id').isNotNull(), 'PRIVATE').otherwise(col('a.privacy')).alias('req_value'))
df_s.show()
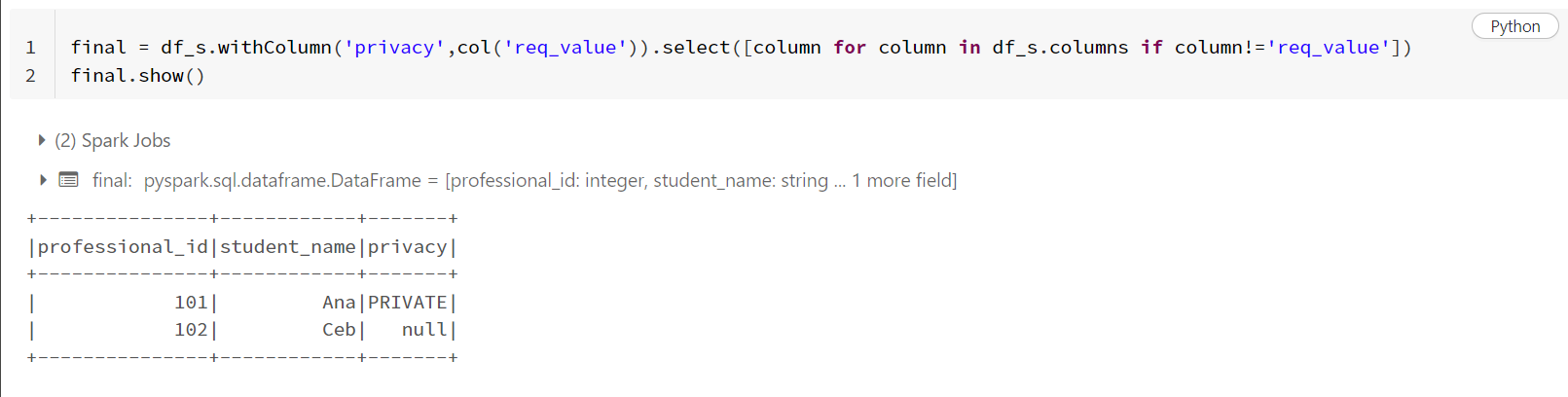
- Since, from the above,
req_valueis the column with required values and these values need to be reflected inprivacy, you can use the following code directly.
final = df_s.withColumn('privacy',col('req_value')).select([column for column in df_s.columns if column!='req_value'])
final.show()
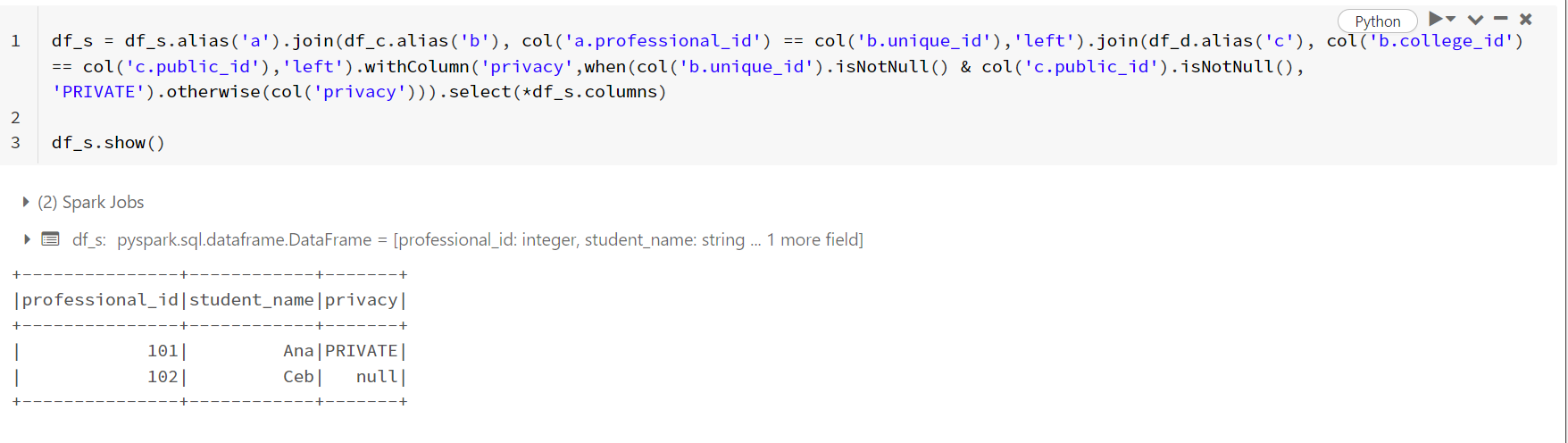
UPDATE:
You can also use the following code where I have updated the column using withColumn instead of select.
df_s = df_s.alias('a').join(df_c.alias('b'), col('a.professional_id') == col('b.unique_id'),'left').join(df_d.alias('c'), col('b.college_id') == col('c.public_id'),'left').withColumn('privacy',when(col('b.unique_id').isNotNull() & col('c.public_id').isNotNull(), 'PRIVATE').otherwise(col('privacy'))).select(*df_s.columns)
#or you can use this as well, without using alias.
#df_s = df_s.join(df_c, df_s['professional_id'] == df_c['unique_id'],'left').join(df_d, df_c['college_id'] == df_d['public_id'],'left').withColumn('privacy',when(df_c['unique_id'].isNotNull() & df_d['public_id'].isNotNull(), 'PRIVATE').otherwise(df_s['privacy'])).select(*df_s.columns)
df_s.show()
CodePudding user response:
After the joins, you can use nvl2. It can check if the join with the last dataframe (df_dept) was successful, if yes, then you can return "PRIVATE", otherwise the value from df_stud.PRIVACY.
Inputs:
from pyspark.sql import functions as F
df_stud = spark.createDataFrame([(1, 'x'), (2, 'STAY')], ['PROFESSIONALID', 'PRIVACY'])
df_college = spark.createDataFrame([(1, 1)], ['COLLEGEID', 'UNIQUEID'])
df_dept = spark.createDataFrame([(1,)], ['PUBLICID'])
df_stud.show()
# -------------- -------
# |PROFESSIONALID|PRIVACY|
# -------------- -------
# | 1| x|
# | 2| STAY|
# -------------- -------
Script:
df = (df_stud.alias('s')
.join(df_college.alias('c'), F.col('s.PROFESSIONALID') == F.col('c.UNIQUEID'), 'left')
.join(df_dept.alias('d'), F.col('c.COLLEGEID') == F.col('d.PUBLICID'), 'left')
.select(
*[f's.`{c}`' for c in df_stud.columns if c != 'PRIVACY'],
F.expr("nvl2(d.PUBLICID, 'PRIVATE', s.PRIVACY) PRIVACY")
)
)
df.show()
# -------------- -------
# |PROFESSIONALID|PRIVACY|
# -------------- -------
# | 1|PRIVATE|
# | 2| STAY|
# -------------- -------