import csv
from email import header
from fileinput import filename
from tokenize import Name
import requests
from bs4 import BeautifulSoup
url = "https://www.azlyrics.com/l/linkinpark.html"
r=requests.get(url)
htmlContent = r.content
soup = BeautifulSoup(htmlContent,"html.parser")
albumList=[]
table = soup.find('div', id="listAlbum")
for row in table.find_all('div', class_="album"):
albumName = {}
albumName['Name'] = row.b.text
albumList.append(albumName)
print(albumName)
noOfAlbum = len(albumList)
print(noOfAlbum)
with open('lpalbumr6.csv','w',encoding='utf8',newline='') as f:
thewriter = csv.writer(f)
header=['Name']
thewriter.writerow(header)
for i in albumList:
thewriter.writerow(albumName)
Hello,
I was trying to get the list of album on artist page on azlyrics.com. When I export the list in csv, I am getting exported list as follows:
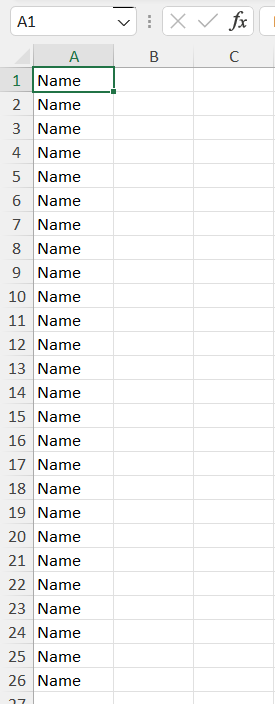
print(albumName) works perfectly, but exported csv looks like above image.
CodePudding user response:
albumList contains all the information you need, so the issue is just with the part where you write the csv at the end.
You have:
for i in albumList:
thewriter.writerow(albumName)
but albumName is not referring to the elements of albumList - it's the temporary variable you used when creating that list. You need to refer to the loop variable i in the loop. You also need to specify that you need the value of the Name key in each dictionary:
for i in albumList:
thewriter.writerow([i['Name']])
This is all inside an extra [] because of the way csvwriter handles strings (see 