I made an example data frame for my situation:
df <- data.frame(ID=c(1,2,3,4), AGE1=c(25,32,29,45), AGE2=c(27,34,31,47), AGE3=c(29,36,33,49), AGE4=c(31,38,35,51), SCORE1=c(20,9,12,19), SCORE2=c(9,10,17,12), SCORE3=c(15,12,13,15), SCORE4=c(13,12,8,12))
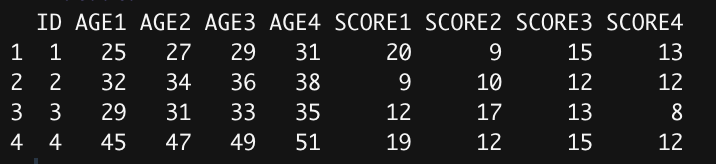
The format of my data frame is longitudinal, so the age of each person increases with each response, and the corresponding scores are also recorded. AGE1 corresponds to SCORE1, AGE2 with SCORE2, etc.
In the end, the x-axis should be ages and the y-axis should be scores. Each row should have their own line with 4 data points.
I made what the data frame should look like (after the transformation). Then I can group by ID and overlay the lines onto the plot, I think:
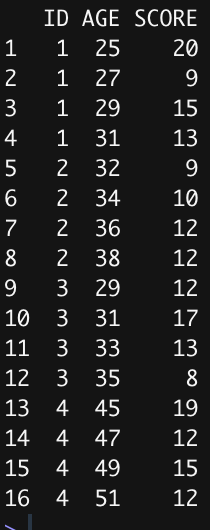
It seems like I would have to use pivot_longer or melt but I wasn't able to figure out how to map each age column with the score columns. Any help would be appreciated.
CodePudding user response:
Three possible ways:
- Use
pivot_longerfromtidyrwithnames_separgument. For this we rename all relevant columns to put in a separator (here we use_) - Use
pivot_longerfromtidyrwithnames_patternargument. Here we do not have to rename the columns, but we have to use special regex:"(.*?)(\\d )$" - Use
pivot_longerfromtidyrwithnames_separgument but without renaming again with special regex:
Way 1:
library(dplyr)
library(tidyr)
library(stringr)
df %>%
rename_with(., ~str_replace(., 'E', 'E_')) %>%
pivot_longer(
cols = -ID,
names_to = c(".value", "name"),
names_sep = "_") %>%
select(-name)
Way 2:
library(dplyr)
library(tidyr)
df %>%
pivot_longer(
cols = -ID,
names_to = c(".value", "name"),
names_pattern = "(.*?)(\\d )$") %>%
select(-name)
Way 3:
library(dplyr)
library(tidyr)
df %>%
pivot_longer(
cols = -ID,
names_to = c(".value", "name"),
names_sep = "(?<=[A-Za-z])(?=[0-9])") %>%
select(-name)
ID AGE SCORE
<dbl> <dbl> <dbl>
1 1 25 20
2 1 27 9
3 1 29 15
4 1 31 13
5 2 32 9
6 2 34 10
7 2 36 12
8 2 38 12
9 3 29 12
10 3 31 17
11 3 33 13
12 3 35 8
13 4 45 19
14 4 47 12
15 4 49 15
16 4 51 12
CodePudding user response:
Perhaps you want to do this finally (this is extension of my friends answer though)
df %>%
pivot_longer(
cols = -ID,
names_to = c(".value", "name"),
names_pattern = "(.*?)(\\d )$") %>%
ggplot(aes(AGE, SCORE, group = ID, color = as.factor(ID)))
geom_point()
geom_line()