With a dataframe
df = pd.DataFrame([['a', 3], ['a', 5], ['a', 2], ['a', 6], ['a', 7], ['a', 1], ['a', 9], ['b', 7], ['b', 8], ['b', 11], ['b', 9], ['b', 10], ['b', 6]], columns = ['k', 'v'])
I want to compute the row difference on column v for each group of column k with a period of 3. While for the first few rows in each group that have less than 3 values, we use an incrementing period starting at 1 till the preset value 3. The desired result would be as follows:
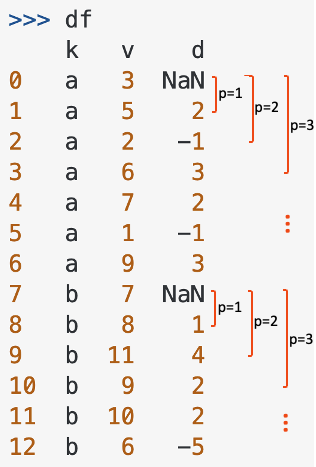
What's a good "pandasonic" way to do this?
CodePudding user response:
Using .groupby() and .rolling() you can achieve what you want:
>>> grouped = (df.
groupby('k')['v'].
rolling(window=4, min_periods=1).
apply(lambda x: x.iloc[-1] - x.iloc[0]).
reset_index().
rename(columns={'v': 'diff'}).drop('level_1', axis=1))
k diff
0 a 0.0
1 a 2.0
2 a -1.0
3 a 3.0
4 a 2.0
5 a -1.0
6 a 3.0
7 b 0.0
8 b 1.0
9 b 4.0
10 b 2.0
11 b 2.0
12 b -5.0
By passing in min_periods=1 to .rolling() the window will start at 1 and increment until either the window value is reached or the max possible period is reached -- whichever happens first.
You could then use .concat() or .merge() to join this back onto df.
CodePudding user response:
groupby diff and use fillna
g = df.groupby('k')['v']
g.diff(3).fillna(g.diff(2).fillna(g.diff(1)))