I made three conditional selections on my dataframe. So lets say:
final_df[(final_df['acceptance_advice'] == 'standard') & (final_df['acceptance'] == 'ok')]
final_df[(final_df['acceptance_advice'] == 'not accepted') & (final_df['acceptance'] == 'ok')]
final_df[(final_df['acceptance_advice'] == 'postponed') & (final_df['acceptance'] == 'declined')]
Now I want to add a categorical variable (the class I am going to use for prediction) from each of these selections. So let's say: the first selection should be class 1 and the second should class 2 and the third selection should be class 3.
I have tried:
cat_1 = final_df[(final_df['acceptance_advice'] == 'standard') & (final_df['acceptance'] == 'ok')]
cat_2 = final_df[(final_df['acceptance_advice'] == 'not accepted') & (final_df['acceptance'] == 'ok')]
cat_3 = final_df[(final_df['acceptance_advice'] == 'postponed') & (final_df['acceptance'] == 'declined')]
final_df['class'] = (cat_1 | cat_2 | cat_3).astype(int)
But it only worked on two categories (e.g. 0 and 1) but not on three.
final_df looks something like this:
| id | feature1 | feature2 | acceptance_advice | acceptance |
|---|---|---|---|---|
| some value | some value | some value | some value | some value |
| some value | some value | some value | some value | some value |
| some value | some value | some value | some value | some value |
| some value | some value | some value | some value | some value |
I want it to look like this:
| id | feature1 | feature2 | acceptance_advice | acceptance | class |
|---|---|---|---|---|---|
| some value | some value | some value | some value | some value | 1 |
| some value | some value | some value | some value | some value | 2 |
| some value | some value | some value | some value | some value | 1 |
| some value | some value | some value | some value | some value | 3 |
I want to add a column class, which should be the class to be predicted.
CodePudding user response:
Maybe like this?
import pandas as pd
# Data thing - we can skip it
id = [0,1,2,3,4,5]
acceptance_advice = ['standard','not accepted','postponed','standard','not accepted','postponed']
acceptance = ['ok','ok','declined','ok','ok','declined']
data = [id, acceptance_advice, acceptance]
df = pd.DataFrame(columns= ['id','acceptance_advice', 'acceptance','class'])
df['id'] = id
df['acceptance_advice'] = acceptance_advice
df['acceptance'] = acceptance
# ============================== Process ==================================
df = df.reset_index() # make sure indexes pair with number of rows (use one time)
label = []
for index, row in df.iterrows():
# print(row['acceptance_advice'], row['acceptance'])
if (row['acceptance_advice'] == 'standard') & (row['acceptance'] == 'ok'):
label.append(1)
elif (row['acceptance_advice'] == 'not accepted') & (row['acceptance'] == 'ok'):
label.append(2)
elif (row['acceptance_advice'] == 'postponed') & (row['acceptance'] == 'declined'):
label.append(3)
df['class'] = label
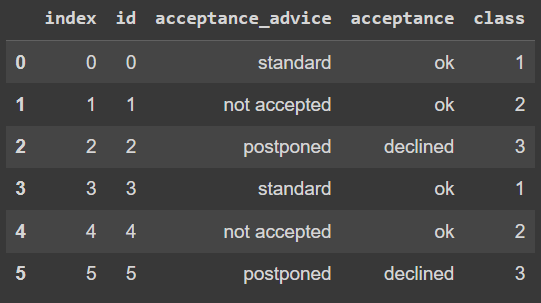
Because you didn't provide us real dataset, i can only set those dataset into the best case from your question. Actually, it have to be at least 6 possibility class (3 from accep_advice, and 2 from acceptance -> 3x2 = 6), That's the reason i use elif in the last condition (to make it strict).
CodePudding user response:
You can test the following to add a class column -
def set_class(df):
if (df['acceptance_advice'] == 'standard') & (df['acceptance'] == 'ok'):
return "1"
elif (df['acceptance_advice'] == 'not accepted') & (df['acceptance'] == 'ok'):
return "2"
elif (df['acceptance_advice'] == 'postponed') & (df['acceptance'] == 'declined'):
return "3"
df['class'] = df.apply(set_class, axis = 1)