I would like to generate pandas dataframes with simulated data.
There should be x sets of columns.
Each set corresponds to y number of columns.
Each set should have a value, a, in z number of rows. The value, a, is a float.
However, z may be different for the different sets of column sets.
The remaining columns will have another value, b, which is also a float.
I would like to write a function to generate such pandas data frames where I can specify the variables x, y, a, b and where a specific value for z can be set for the individual column sets.
Here is an example df:
data = [[0.5, 0.5, 0.1, 0.1, 0.1, 0.1], [0.1, 0.1, 0.5, 0.5, 0.1, 0.1], [0.1, 0.1, 0.1, 0.1, 0.5, 0.5]]
df = pd.DataFrame(data, columns=['set1_col1', 'set1_col2', 'set2_col1', 'set2_col2', 'set3_col1', 'set3_col2'])
df
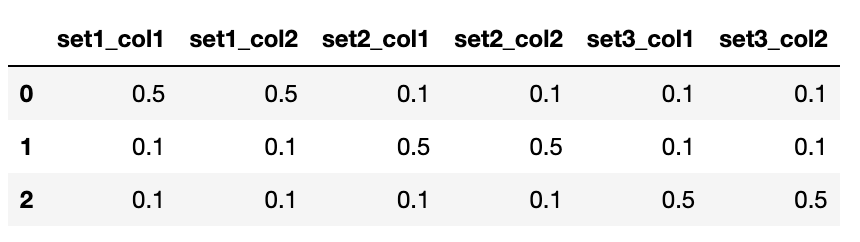
But I would like to be able to specify the variables, which for the above example would be:
x = 3 #(set1, set2, set3)
y = 2 #(col1, col2 for each set)
a = 0.5
z = 1 #(for all column sets)
b = 0.1
Advice on this would be greatly appreciated!
Thanks!
CodePudding user response:
Use numpy.random.choice:
N = 5 #No of rows
x = 3 #(set1, set2, set3)
y = 2 #(col1, col2 for each set)
a = 0.5
z = 1 #(for all column sets)
b = 0.1
#names of sets
sets = [f'set{w 1}' for w in range(x)]
#names of columns
cols = [f'col{w 1}' for w in range(y)]
#MultiIndex by product
mux = pd.MultiIndex.from_product([sets, cols])
#DataFrame with default value
df = pd.DataFrame(b, index=range(N), columns=mux)
#random assign a by random index with no repeat
for c, i in zip(df.columns.levels[0], np.random.choice(df.index, z * x, replace=False)):
df.loc[i, c] = a
df.columns = df.columns.map(lambda x: f'{x[0]}_{x[1]}')
print (df)
set1_col1 set1_col2 set2_col1 set2_col2 set3_col1 set3_col2
0 0.1 0.1 0.1 0.1 0.1 0.1
1 0.1 0.1 0.5 0.5 0.1 0.1
2 0.5 0.5 0.1 0.1 0.1 0.1
3 0.1 0.1 0.1 0.1 0.1 0.1
4 0.1 0.1 0.1 0.1 0.5 0.5
EDIT: For consecutive random values use:
N = 6 #No of rows
x = 3 #(set1, set2, set3)
y = 2 #(col1, col2 for each set)
a = 0.5
z = 2 #(for all column sets)
b = 0.1
#names of sets
sets = [f'set{w 1}' for w in range(x)]
#names of columns
cols = [f'col{w 1}' for w in range(y)]
#MultiIndex by product
mux = pd.MultiIndex.from_product([sets, cols])
#DataFrame with default value, index is create by consecutive groups
df = pd.DataFrame(b, index=np.arange(N) // z, columns=mux)
print (df)
#random assign a by random index with no repeat
for c, i in zip(df.columns.levels[0],
np.random.choice(np.unique(df.index), x, replace=False)):
df.loc[i, c] = a
df.columns = df.columns.map(lambda x: f'{x[0]}_{x[1]}')
df = df.reset_index(drop=True)
print (df)
set1_col1 set1_col2 set2_col1 set2_col2 set3_col1 set3_col2
0 0.5 0.5 0.1 0.1 0.1 0.1
1 0.5 0.5 0.1 0.1 0.1 0.1
2 0.1 0.1 0.1 0.1 0.5 0.5
3 0.1 0.1 0.1 0.1 0.5 0.5
4 0.1 0.1 0.5 0.5 0.1 0.1
5 0.1 0.1 0.5 0.5 0.1 0.1