I get a website (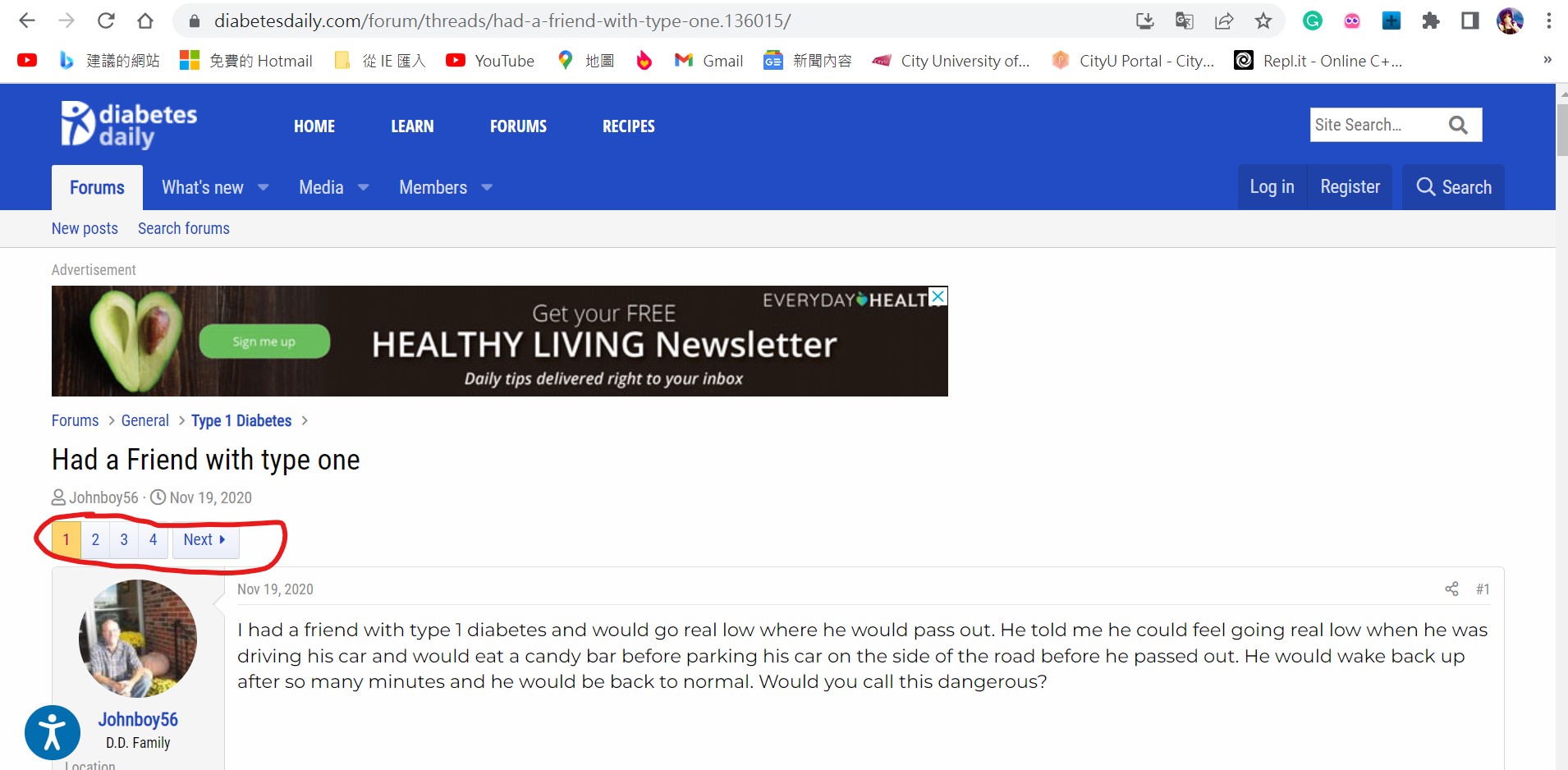
Want to use the for loop for web scrapping, therefore could I ask, how I get the maximum number of forum pages on this page by BeaurifulSoup? Many thanks.
CodePudding user response:
You can try something like this:
import requests
from bs4 import BeautifulSoup as bs
url = "https://www.diabetesdaily.com/forum/threads/had-a-friend-with-type-one.136015/"
req = requests.get(url)
soup = bs(req.content, 'html.parser')
navs = soup.find("ul", { "class" : "pageNav-main" }).find_all("li", recursive=False)
print(navs)
print(f'Length: {len(navs)}')
Result
[<li ><a href="/forum/threads/had-a-friend-with-type-one.136015/">1</a></li>, <li ><a href="/forum/threads/had-a-friend-with-type-one.136015/page-2">2</a></li>, <li ><a href="/forum/threads/had-a-friend-with-type-one.136015/page-3">3</a></li>, <li ><a href="/forum/threads/had-a-friend-with-type-one.136015/page-4">4</a></li>]
Length: 4
CodePudding user response:
You don't need BeautifulSoup to count the number of pages.
URL of page 1 : https://www.diabetesdaily.com/forum/threads/had-a-friend-with-type-one.136015/page-1
URL of page 2 : https://www.diabetesdaily.com/forum/threads/had-a-friend-with-type-one.136015/page-2
URL of page 3 : https://www.diabetesdaily.com/forum/threads/had-a-friend-with-type-one.136015/page-3
And so on...
So you need to increment the value X in https://www.diabetesdaily.com/forum/threads/had-a-friend-with-type-one.136015/page-X to move to the next page. You can then check the status code of the response and the page title to ensure that we are not visiting the same page twice.
import requests
import re
def getPageTitle(response_text):
d = re.search('<\W*title\W*(.*)</title', response_text, re.IGNORECASE)
return d.group(1)
def count_pages():
count = 0
uniquePages = set()
while(True):
count = 1
url = ('https://www.diabetesdaily.com/forum/threads/'
f'had-a-friend-with-type-one.136015/page-{count}')
response = requests.get(url)
title = getPageTitle(response.text)
if title in uniquePages or response.status_code != 200:
break
uniquePages.add(title)
return len(uniquePages)
print(count_pages()) # 4