I am trying to extract from URL str "/used/Mercedes-Benz/2021-Mercedes-Benz-Sprinte..." the entire Make name, i.e. "Mercedes-Benz" BUT my pattern only returns the first letter, i.e. "M"
Please help me come up with the correct pattern to use on pandas df.
Thank you
CODE:
URLS_by_City['Make'] = URLS_by_City['Page'].str.extract('. ([A-Z])\w (?=[\/]) ', expand=True) Clean_Make = URLS_by_City.dropna(subset=["Make"]) Clean_Make # WENT FROM 5K rows --> to 2688 rows
Page City Pageviews Unique Pageviews Avg. Time on Page Entrances Bounce Rate % Exit **Make**
71 /used/Mercedes-Benz/2021-Mercedes-Benz-Sprinte... San Jose 310 149 00:00:27 149 2.00% 47.74% **B**
103 /used/Audi/2015-Audi-SQ5-286f67180a0e09a872992... Menlo Park 250 87 00:02:36 82 0.00% 32.40% **A**
158 /used/Mercedes-Benz/2021-Mercedes-Benz-Sprinte... San Francisco 202 98 00:00:18 98 2.04% 48.02% **B**
165 /used/Audi/2020-Audi-S8-c6df09610a0e09af26b5cf... San Francisco 194 93 00:00:42 44 2.22% 29.38% **A**
168 /used/Mercedes-Benz/2021-Mercedes-Benz-Sprinte... (not set) 192 91 00:00:11 91 2.20% 47.40% **B**
... ... ... ... ... ... ... ... ... ...
4995 /used/Subaru/2019-Subaru-Crosstrek-5717b3040a0... Union City 10 3 00:02:02 0 0.00% 30.00% **S**
4996 /used/Tesla/2017-Tesla-Model S-15605a190a0e087... San Jose 10 5 00:01:29 5 0.00% 50.00% **T**
4997 /used/Tesla/2018-Tesla-Model 3-0f3ea14d0a0e09a... Las Vegas 10 4 00:00:09 2 0.00% 40.00% **T**
4998 /used/Tesla/2018-Tesla-Model 3-0f3ea14d0a0e09a... Austin 10 4 00:03:29 2 0.00% 40.00% **T**
4999 /used/Tesla/2018-Tesla-Model 3-5f29cdc70a0e09a... Orinda 10 4 00:04:00 1 0.00% 0.00% **T**
TRIED: `example_url = "/used/Mercedes-Benz/2021-Mercedes-Benz-Sprinter 2500-9f3d32130a0e09af63592c3c48ac5c24.htm?store_code=AudiOakland&ads_adgroup=139456079219&ads_adid=611973748445&ads_digadprovider=adpearance&adpdevice=m&campaign_id=17820707224&adpprov=1" pattern = ". ([a-zA-Z0-9()])\w (?=[/]) "
wanted_make = URLS_by_City['Page'].str.extract(pattern)
wanted_make
` 0 0 r 1 r 2 NaN 3 NaN 4 r ... ... 4995 r 4996 l 4997 l 4998 l 4999 l
It worked in regex online tool.
but unfortunately not in my jupyter notebook
EXAMPLE PATTERNS - I bolded what should match: /used/Mercedes-Benz/2021-Mercedes-Benz-Sprinter 2500-9f3d32130a0e09af63592c3c48ac5c24.htm?store_code=AudiOakland&ads_adgroup=139456079219&ads_adid=611973748445&ads_digadprovider=adpearance&adpdevice=m&campaign_id=17820707224&adpprov=1 /used/Audi/2020-Audi-S8-c6df09610a0e09af26b5cff998e0f96e.htm /used/Mercedes-Benz/2021-Mercedes-Benz-Sprinter 2500-9f3d32130a0e09af63592c3c48ac5c24.htm?store_code=AudiOakland&ads_adgroup=139456079219&ads_adid=611973748445&ads_digadprovider=adpearance&adpdevice=m&campaign_id=17820707224&adpprov=1 /used/Audi/2021-Audi-RS 5-b92922bd0a0e09a91b4e6e9a29f63e8f.htm /used/LEXUS/2018-LEXUS-GS 350-dffb145e0a0e09716bd5de4955662450.htm /used/Porsche/2014-Porsche-Boxster-0423401a0a0e09a9358a179195e076a9.htm /used/Audi/2014-Audi-A6-1792929d0a0e09b11bc7e218a1fa7563.htm /used/Honda/2018-Honda-Civic-8e664dd50a0e0a9a43aacb6d1ab64d28.htm /new-inventory/index.htm?normalFuelType=Hybrid&normalFuelType=Electric /used-inventory/index.htm /new-inventory/index.htm /new-inventory/index.htm?normalFuelType=Hybrid&normalFuelType=Electric /
CodePudding user response:
I would use:
URLS_by_City["Make"] = URLS_by_City["Page"].str.extract(r'([^/] )/\d{4}\b')
This targets the URL path segment immediately before the portion with the year. You could also try this version:
URLS_by_City["Make"] = URLS_by_City["Page"].str.extract(r'/[^/] /([^/] )')
CodePudding user response:
I have tried completing your requirement in Jupyter Notebook.
PFB the code and screenshots:
- I have created a dummy pandas dataframe(data_df), below is a screenshot of the same
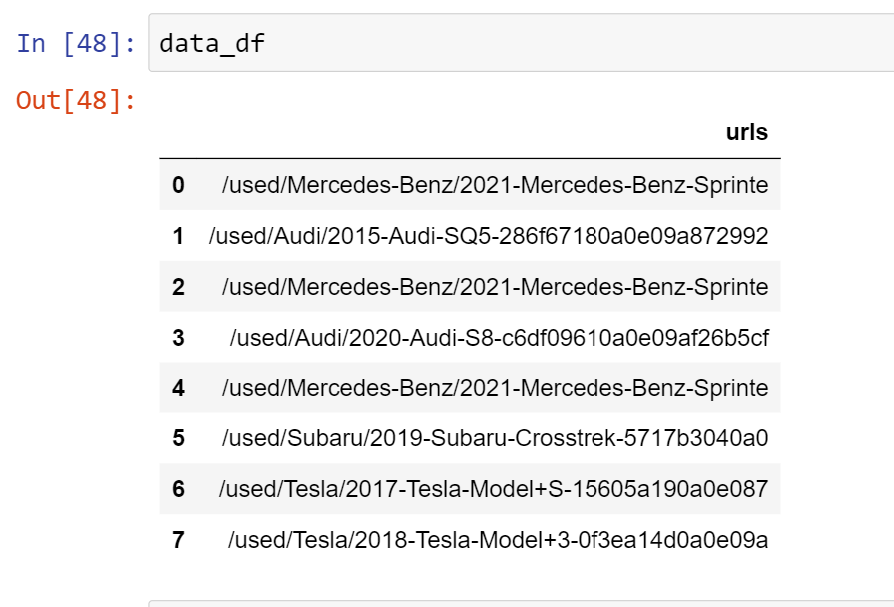
I have created a pattern based on the pattern of the string to be extracted
pattern = "^/used/(.*)/(?=[20][0-9{2}])"
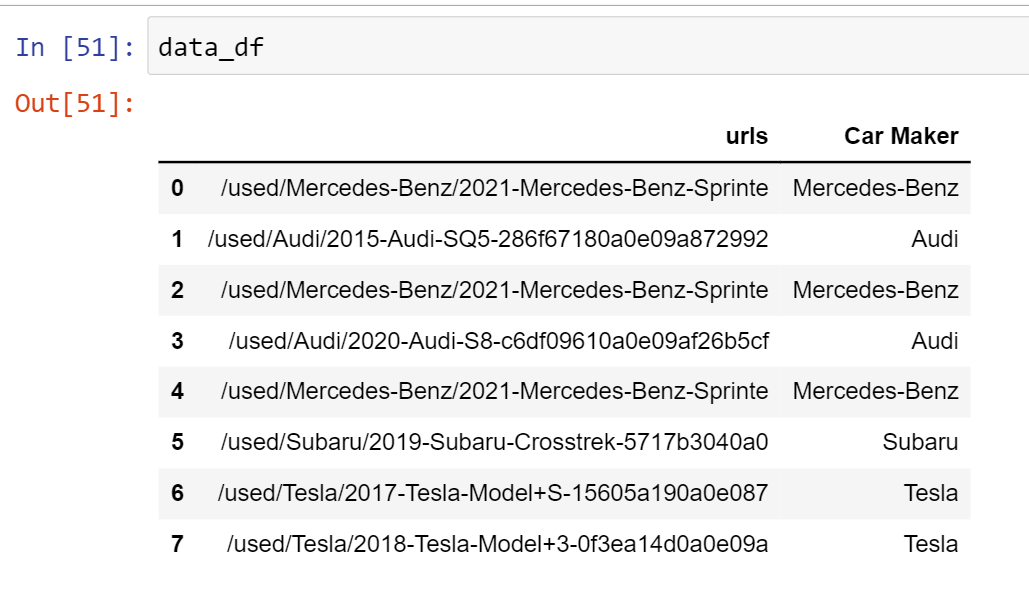
Used the patten to extract required data from the URLs and saved it in another column in the same dataframe
data_df['Car Maker'] = data_df['urls'].str.extract(pattern)
Below is a screenshot of the output
I hope this is helpful..