I am trying to get the list of company names from : 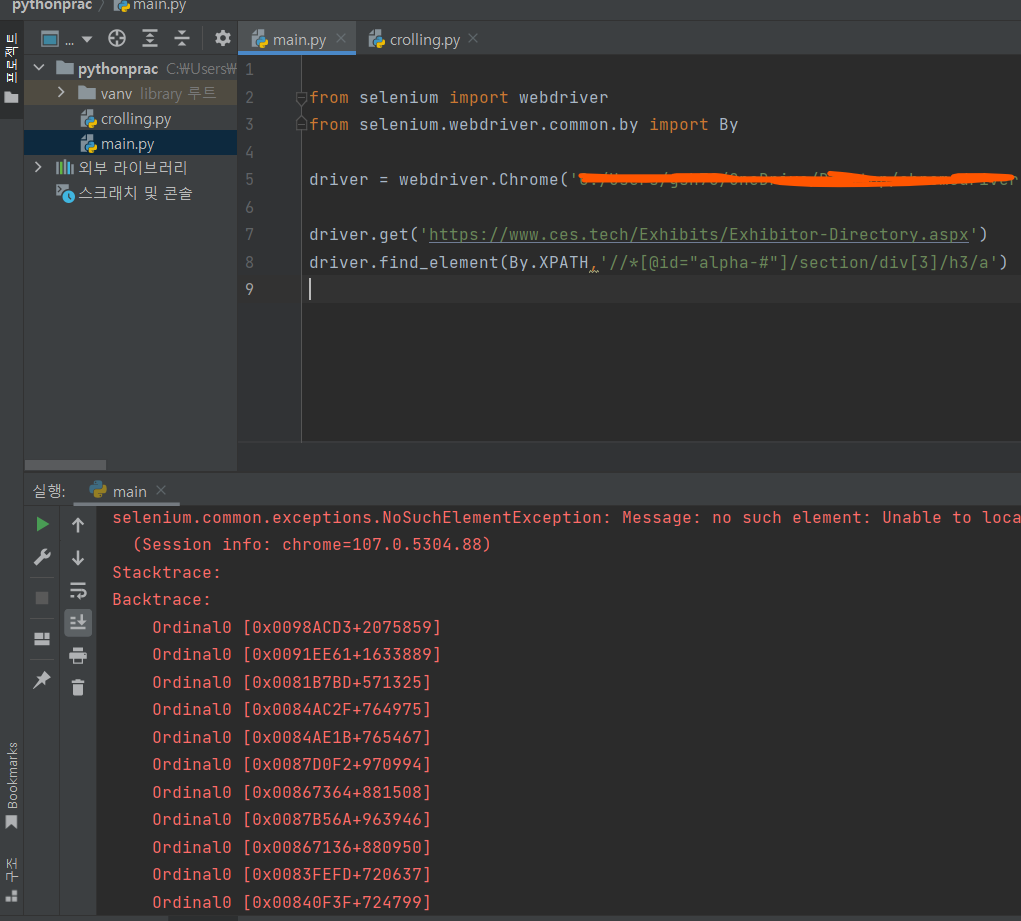
Thank you in advance.
I tried SELECTOR XPATH and TAG_NAME('a') Print('company-name')
CodePudding user response:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
'ctaapi-version': '1.1'
}
def main(url):
with requests.Session() as req:
req.headers.update(headers)
params = {
"alpha": "",
"country": "",
"exhibitorType": "",
"pageNo": "1",
"pageSize": "30",
"searchTerm": "",
"sortBy": "alpha",
"state": "",
"venue": ""
}
r = req.get(
'https://www.ces.tech/api/Exhibitors', params=params)
print(r.json())
main('https://www.ces.tech/Exhibits/Exhibitor-Directory.aspx')
CodePudding user response:
Assuming what you have highlighted is what you want, I think the XPath would be something like:
names = driver.find_elements(By.XPATH, '//h3[@]//a')
This would save all of the matching elements in the names variable. Then if there are multiple of these and you are trying to get the text then you could loop through them like this:
for i in names:
print(i.text)