Im trying to flatten 2 columns from a table loaded into a dataframe as below:
| u_group | t_group |
|---|---|
| {"link": "https://hi.com/api/now/table/system/2696f18b376bca0", "value": "2696f18b376bca0"} | {"link": "https://hi.com/api/now/table/system/2696f18b376bca0", "value": "2696f18b376bca0"} |
| {"link": "https://hi.com/api/now/table/system/99b27bc1db761f4", "value": "99b27bc1db761f4"} | {"link": "https://hi.com/api/now/table/system/99b27bc1db761f4", "value": "99b27bc1db761f4"} |
I want to separate them and get them as:
| u_group.link | u_group.value | t_group.link | t_group.value |
|---|---|---|---|
| https://hi.com/api/now/table/system/2696f18b376bca0 | 2696f18b376bca0 | https://hi.com/api/now/table/system/2696f18b376bca0 | 2696f18b376bca0 |
| https://hi.com/api/now/table/system/99b27bc1db761f4 | 99b27bc1db761f4 | https://hi.com/api/now/table/system/99b27bc1db761f4 | 99b27bc1db761f4 |
I used the below code, but wasnt successful.
import ast
from pandas.io.json import json_normalize
df12 = spark.sql("""select u_group,t_group from tbl""")
def only_dict(d):
'''
Convert json string representation of dictionary to a python dict
'''
return ast.literal_eval(d)
def list_of_dicts(ld):
'''
Create a mapping of the tuples formed after
converting json strings of list to a python list
'''
return dict([(list(d.values())[1], list(d.values())[0]) for d in ast.literal_eval(ld)])
A = json_normalize(df12['u_group'].apply(only_dict).tolist()).add_prefix('link.')
B = json_normalize(df['u_group'].apply(list_of_dicts).tolist()).add_prefix('value.')
TypeError: 'Column' object is not callable
Kindly help or suggest if any other code would work better.
CodePudding user response:
need simple example and code for answer
example:
data = [[{'link':'A1', 'value':'B1'}, {'link':'A2', 'value':'B2'}],
[{'link':'C1', 'value':'D1'}, {'link':'C2', 'value':'D2'}]]
df = pd.DataFrame(data, columns=['u', 't'])
output(df):
u t
0 {'link': 'A1', 'value': 'B1'} {'link': 'A2', 'value': 'B2'}
1 {'link': 'C1', 'value': 'D1'} {'link': 'C2', 'value': 'D2'}
use following code:
pd.concat([df[i].apply(lambda x: pd.Series(x)).add_prefix(i '_') for i in df.columns], axis=1)
output:
u_link u_value t_link t_value
0 A1 B1 A2 B2
1 C1 D1 C2 D2
CodePudding user response:
Here are my 2 cents,
A simple way to achieve this using PYSPARK.
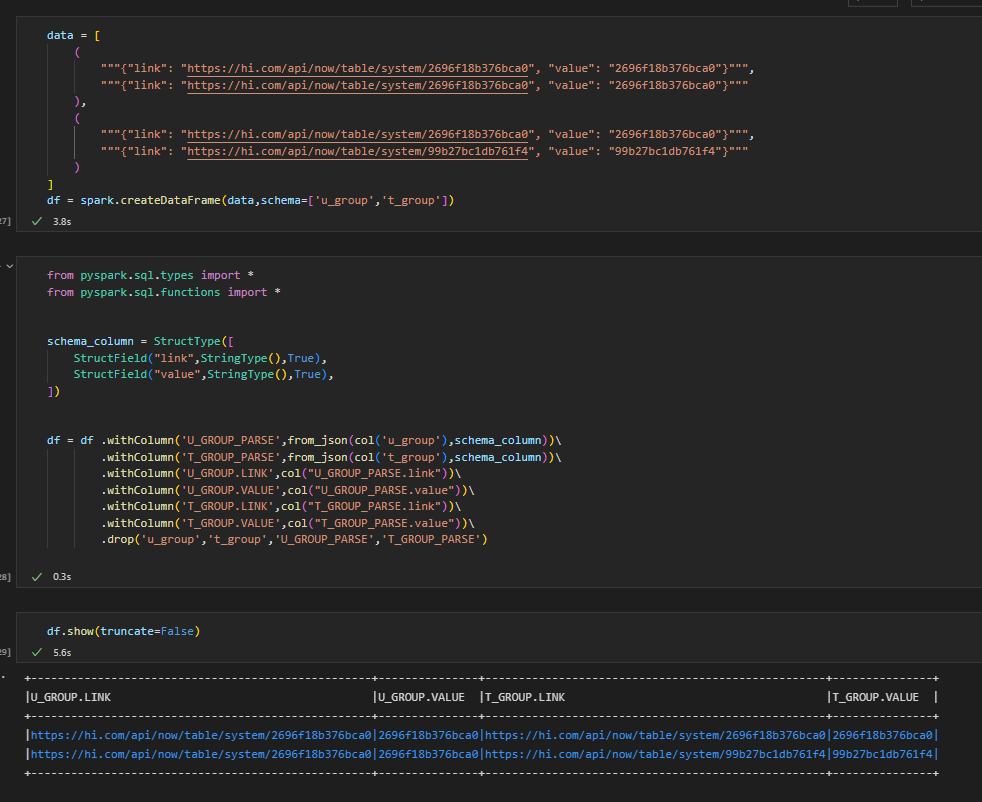
Create the dataframe as follows:
data = [ ( """{"link": "https://hi.com/api/now/table/system/2696f18b376bca0", "value": "2696f18b376bca0"}""", """{"link": "https://hi.com/api/now/table/system/2696f18b376bca0", "value": "2696f18b376bca0"}""" ), ( """{"link": "https://hi.com/api/now/table/system/2696f18b376bca0", "value": "2696f18b376bca0"}""", """{"link": "https://hi.com/api/now/table/system/99b27bc1db761f4", "value": "99b27bc1db761f4"}""" ) ] df = spark.createDataFrame(data,schema=['u_group','t_group'])Then use the from_json() to parse the dictionary and fetch the individual values as follows:
from pyspark.sql.types import * from pyspark.sql.functions import * schema_column = StructType([ StructField("link",StringType(),True), StructField("value",StringType(),True), ]) df = df .withColumn('U_GROUP_PARSE',from_json(col('u_group'),schema_column))\ .withColumn('T_GROUP_PARSE',from_json(col('t_group'),schema_column))\ .withColumn('U_GROUP.LINK',col("U_GROUP_PARSE.link"))\ .withColumn('U_GROUP.VALUE',col("U_GROUP_PARSE.value"))\ .withColumn('T_GROUP.LINK',col("T_GROUP_PARSE.link"))\ .withColumn('T_GROUP.VALUE',col("T_GROUP_PARSE.value"))\ .drop('u_group','t_group','U_GROUP_PARSE','T_GROUP_PARSE')Print the dataframe
df.show(truncate=False)
Please check the below image for your reference: