I am reading excel data columns Item, Month and Index value...
LowestCostItems = pd.read_excel('lowest_cost_items_dataset.xlsx')
Item Date Index value (April 2021 = 100)
All items 2021-04 100
All items 2021-05 100.2
All items 2021-06 99.7
All items 2021-07 100
All items 2021-08 100.9
All items 2021-09 99.5
All items 2021-10 103.4
All items 2021-11 103.2
All items 2021-12 104.9
All items 2022-01 105.6
Apples 2021-04 100
Apples 2021-05 100.1
Apples 2021-06 100.3
Apples 2021-07 99.6
Apples 2021-08 101.2
Apples 2021-09 88.6
Apples 2021-10 99.3
Apples 2021-11 93.5
Apples 2021-12 97.6
Apples 2022-01 99.4
Baked beans 2021-04 100
Baked beans 2021-05 100
Baked beans 2021-06 100
Baked beans 2021-07 100.1
Baked beans 2021-08 101.4
Baked beans 2021-09 101.4
Baked beans 2021-10 106.1
Baked beans 2021-11 111.6
Baked beans 2021-12 112
Baked beans 2022-01 115.1
I am trying to switch columns and rows to create a new csv file. I can aggregate data by Date and Item column
LowestCostItems.groupby(['Date','Item']).agg({"Index value (April 2021 = 100)": lambda x:(x)})
i am unable to figure out what i need to do so that First column should become Date, data in Item row should become a columns headings and their respected values in Index value... should appear underneath each column.
The end result should be :
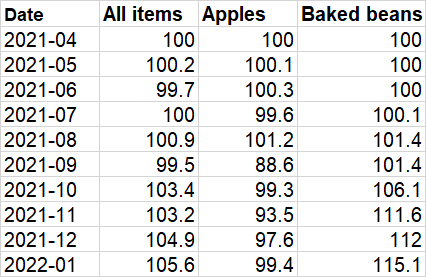
Any help will be much appreciated.
CodePudding user response:
Try:
df = df.pivot(
index="Date", columns="Item", values="Index value (April 2021 = 100)"
).reset_index()
df.columns.name, df.index.name = None, None
print(df)
Prints:
Date All items Apples Baked beans
0 2021-04 100.0 100.0 100.0
1 2021-05 100.2 100.1 100.0
2 2021-06 99.7 100.3 100.0
3 2021-07 100.0 99.6 100.1
4 2021-08 100.9 101.2 101.4
5 2021-09 99.5 88.6 101.4
6 2021-10 103.4 99.3 106.1
7 2021-11 103.2 93.5 111.6
8 2021-12 104.9 97.6 112.0
9 2022-01 105.6 99.4 115.1