When I convert the python float 77422223.0 to a spark FloatType, I get 77422224. If I do so with DoubleType I get 77422223. How is this conversion working and is there a way to compute when such an error will happen?
df = spark.createDataFrame([77422223.0],FloatType())
display(df)
output
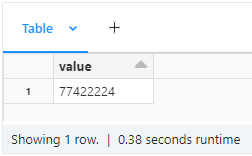
and as expected running
df = spark.createDataFrame([77422223.0],DoubleType())
display(df)
yields
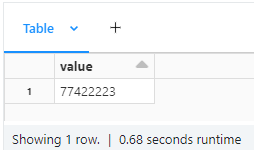
CodePudding user response:
How is this conversion working…
I assume the Spark FloatType is IEEE-754 binary32. This format uses a 24-bit significand and an exponent range from −126 to 127. Each number is represented as a sign and a 24-bit numeral with a “.” after its first digit multiplied by two to the power of an exponent, such as 1.010011000011111000000002•213.
In binary, 77,422,223 is 1001001110101011110100011112. That is 27 bits. So it cannot be represented in the binary32 format. When it is converted to the binary32 format, the conversion operating rounds it to the nearest representable value. That is 1001001110101011110100100002, which has 23 significant digits.
… and is there a way to compute when such an error will happen?
When the number is written in binary, if the number of bits from the first 1 to its last 1, including both of those, is more than 24, then it cannot be represented in the binary32 format.
Also, if the magnitude of the number is less than 2−126, it cannot be represented in binary32 unless it is a multiple of 2−149, including zero. Numbers in this range are subnormal and have a fixed exponent −126, and the lowest bit of the significand has a position value of 2−149. And, if the magnitude number is 2128 or greater, it cannot be represented, unless it is ∞ or −∞.