I'm trying to flatten this json response into a pandas dataframe to export to csv.
It looks like this:
j = [
{
"id": 401281949,
"teams": [
{
"school": "Louisiana Tech",
"conference": "Conference USA",
"homeAway": "away",
"points": 34,
"stats": [
{"category": "rushingTDs", "stat": "1"},
{"category": "puntReturnYards", "stat": "24"},
{"category": "puntReturnTDs", "stat": "0"},
{"category": "puntReturns", "stat": "3"},
],
}
],
}
]
...Many more items in the stats area. If I run this and flatten to the teams level:
multiple_level_data = pd.json_normalize(j, record_path =['teams'])
I get:
school conference homeAway points stats
0 Louisiana Tech Conference USA away 34 [{'category': 'rushingTDs', 'stat': '1'}, {'ca...
How do I flatten it twice so that all of the stats are on their own column in each row?
If I do this:
multiple_level_data = pd.json_normalize(j, record_path =['teams'])
multiple_level_data = multiple_level_data.explode('stats').reset_index(drop=True)
multiple_level_data=multiple_level_data.join(pd.json_normalize(multiple_level_data.pop('stats')))
I end up with multiple rows instead of more columns:
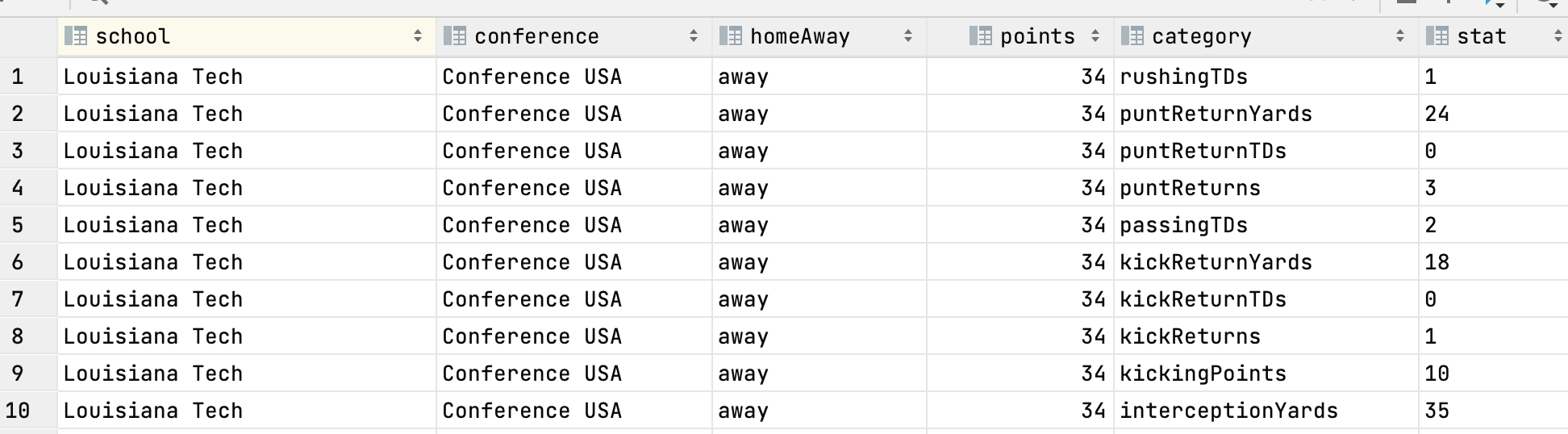
CodePudding user response:
can you try this:
multiple_level_data = pd.json_normalize(j, record_path =['teams'])
multiple_level_data = multiple_level_data.explode('stats').reset_index(drop=True)
multiple_level_data=multiple_level_data.join(pd.json_normalize(multiple_level_data.pop('stats')))
#convert rows to columns.
multiple_level_data=multiple_level_data.set_index(multiple_level_data.columns[0:4].to_list())
dfx=multiple_level_data.pivot_table(values='stat',columns='category',aggfunc=list).apply(pd.Series.explode).reset_index(drop=True)
multiple_level_data=multiple_level_data.reset_index().drop(['stat','category'],axis=1).drop_duplicates().reset_index(drop=True)
multiple_level_data=multiple_level_data.join(dfx)
Output:
| school | conference | homeAway | points | puntReturnTDs | puntReturnYards | puntReturns | rushingTDs | |
|---|---|---|---|---|---|---|---|---|
| 0 | Louisiana Tech | Conference USA | away | 34 | 0 | 24 | 3 | 1 |
CodePudding user response:
You can try:
df = pd.DataFrame(j).explode("teams")
df = pd.concat([df, df.pop("teams").apply(pd.Series)], axis=1)
df["stats"] = df["stats"].apply(lambda x: {d["category"]: d["stat"] for d in x})
df = pd.concat(
[
df,
df.pop("stats").apply(pd.Series),
],
axis=1,
)
print(df)
Prints:
id school conference homeAway points rushingTDs puntReturnYards puntReturnTDs puntReturns
0 401281949 Louisiana Tech Conference USA away 34 1 24 0 3
CodePudding user response:
Instead of calling explode() on an output of a json_normalize(), you can explicitly pass the paths to the meta data for each column in a single json_normalize() call. For example, ['teams', 'school'] would be one path, ['teams', 'conference'] is another path, etc. This will create a long dataframe similar to what you already have.
Then you can call pivot() to reshape this output into the correct shape.
# normalize json
df = pd.json_normalize(
j, record_path=['teams', 'stats'],
meta=['id', *(['teams', c] for c in ('school', 'conference', 'homeAway', 'points'))]
)
# column name contains 'teams' prefix; remove it
df.columns = [c.split('.')[1] if '.' in c else c for c in df]
# pivot the intermediate result
df = (
df.astype({'points': int, 'id': int})
.pivot(['id', 'school', 'conference', 'homeAway', 'points'], 'category', 'stat')
.reset_index()
)
# remove index name
df.columns.name = None
df

CodePudding user response:
This should work:
df = pd.DataFrame(j).explode("teams")
df = pd.concat([df, df.pop("teams").apply(pd.Series)], axis=1)
df["stats"] = df["stats"].apply(lambda x: {d["category"]: d["stat"] for d in x})
df = pd.concat(
[
df,
df.pop("stats").apply(pd.Series),
],
axis=1,
)
print(df)