I'm trying to filter my data by keeping the row that respects a condition AND the row that follows it if it exists:
In the example below, I need to keep the row with "NOK" in "X3" and the next one but if the next one doesnt exist, just keep the row with "NOK".
My data looks like this (Original data have far more rows) :
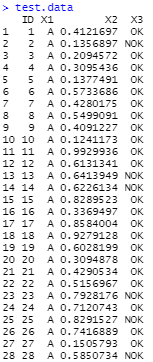
My final result should look like this :
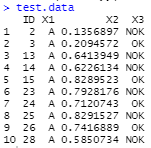
Here's the structure of my data:
structure(list(ID = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28
), X1 = c("A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A"), X2 = c(0.41216973831289, 0.135689706939447,
0.209457162385174, 0.309543570254728, 0.137749096959088, 0.573368605784345,
0.428017532791265, 0.549909139998716, 0.409122667142699, 0.124117306710226,
0.992993602943196, 0.613134107410448, 0.641394855265801, 0.622613385385378,
0.828952257344686, 0.336949690008312, 0.858400408475689, 0.927912763348051,
0.602819926298281, 0.309487756908737, 0.429053378531082, 0.515696657675126,
0.792817566017885, 0.71207432761577, 0.829152651324837, 0.741688856317136,
0.150579318070398, 0.585073373582262), X3 = c("OK", "NOK", "OK",
"OK", "OK", "OK", "OK", "OK", "OK", "OK", "OK", "OK", "NOK",
"NOK", "OK", "OK", "OK", "OK", "OK", "OK", "OK", "OK", "NOK",
"OK", "NOK", "OK", "OK", "NOK")), row.names = c(NA, -28L), class = "data.frame")
Thanks in advance !
CodePudding user response:
Using dplyr::lag(), keep rows where current or previous value is "NOK".
library(dplyr)
test.data %>%
filter(X3 == "NOK" | lag(X3) == "NOK")
ID X1 X2 X3
1 2 A 0.1356897 NOK
2 3 A 0.2094572 OK
3 13 A 0.6413949 NOK
4 14 A 0.6226134 NOK
5 15 A 0.8289523 OK
6 23 A 0.7928176 NOK
7 24 A 0.7120743 OK
8 25 A 0.8291527 NOK
9 26 A 0.7416889 OK
10 28 A 0.5850734 NOK
CodePudding user response:
Base R
df[df$X3=="NOK" | c("",head(df$X3,-1))=="NOK",]
ID X1 X2 X3
2 2 A 0.1356897 NOK
3 3 A 0.2094572 OK
13 13 A 0.6413949 NOK
14 14 A 0.6226134 NOK
15 15 A 0.8289523 OK
23 23 A 0.7928176 NOK
24 24 A 0.7120743 OK
25 25 A 0.8291527 NOK
26 26 A 0.7416889 OK
28 28 A 0.5850734 NOK
CodePudding user response:
you must first get the indexes of the "NOK" lines in a list, then add the next line to this list.
You have to remove the duplicates from the list (when two NOK follow each other).
The if condition allows to delete the last element of the list if it corresponds to NOK in last line of the dataset.
Then it is enough to filter the initial dataset on the listed indexes.
index= which(data$X3 == "NOK")
print(index)
library(dplyr)
index_all = append(index, index 1) %>%
sort(decreasing = F) %>%
unique()
index_all = if(index_all[length(index_all)]>nrow(data)) index_all[- length(index_all)]
data_filter = data[index_all,]