Despite my best efforts to make CoreML MLModel process its predictions in parallel, seems like under-the-hood Apple forcing it to run in a serial/one-by-one manner.
I made a public repository reproducing the PoC of the issue:
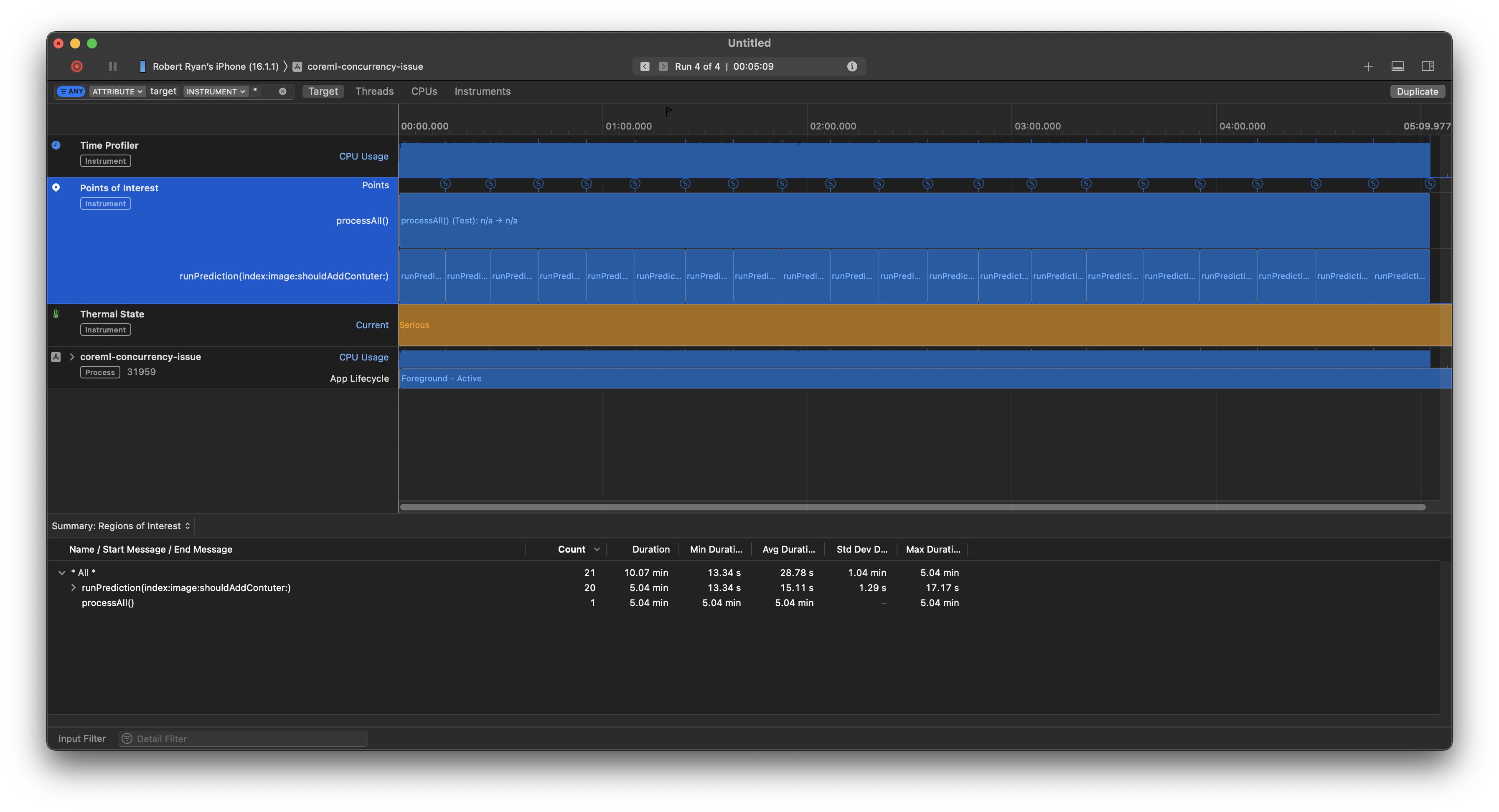
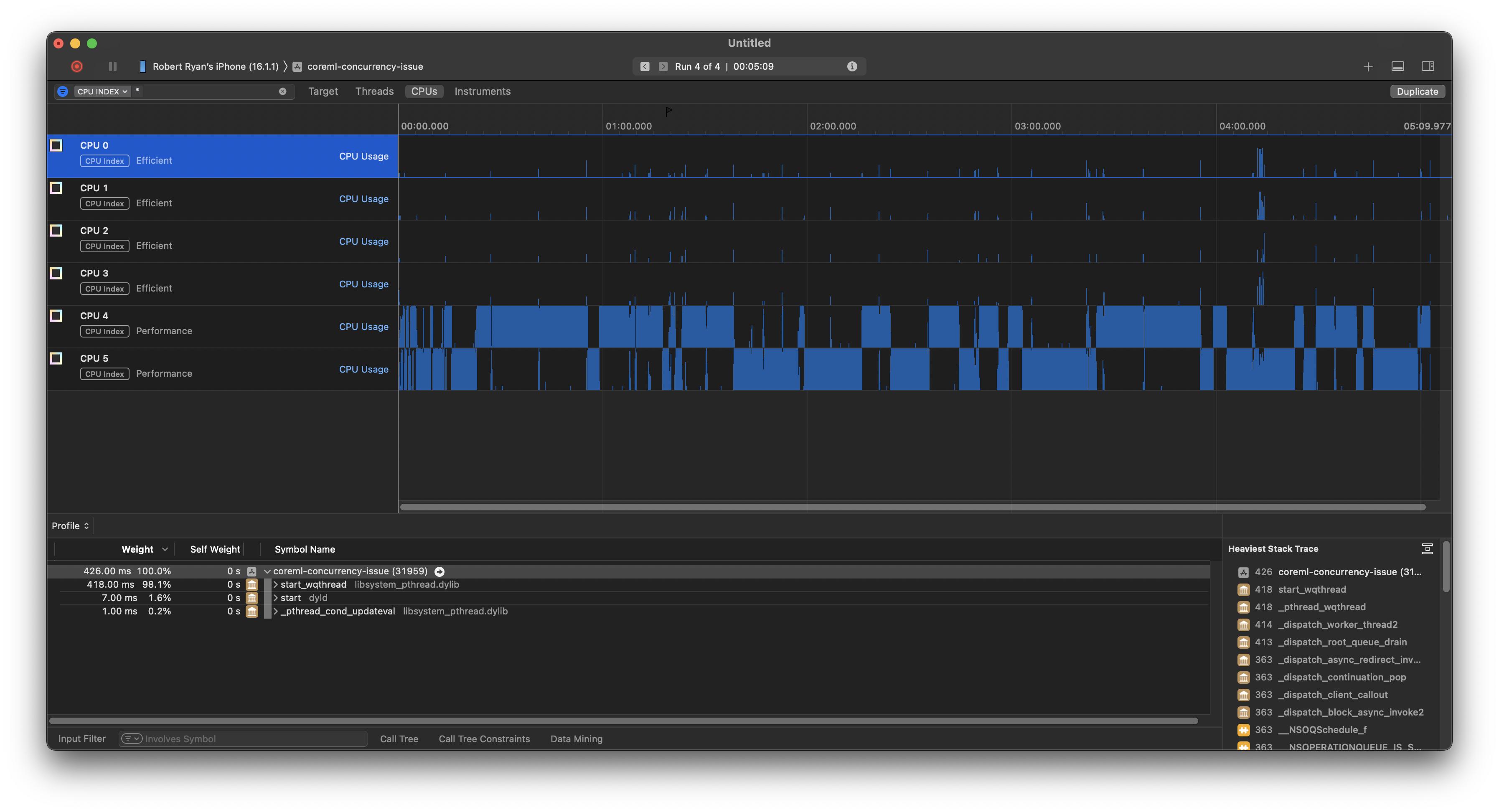
And, if I switch to the CPU view, I can see that it is jumping between two performance cores on my iPhone 12 Pro Max:
That makes sense. OK, now let us change the maxConcurrentOperationCount to 3, the overall processing time (the processingAll function) drops from 5 to 3½ minutes:
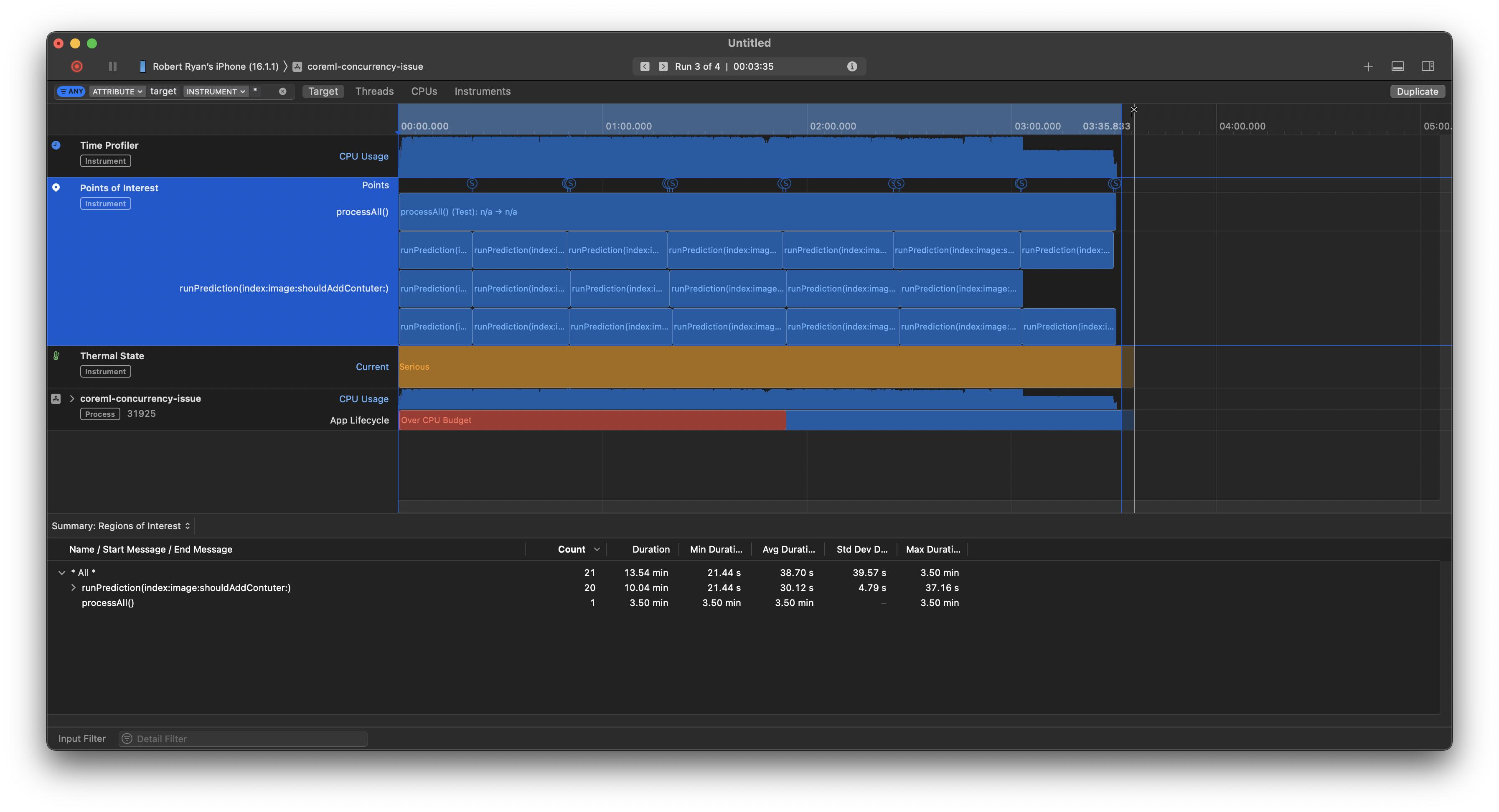
And when I switch to the CPU view, to see what is going on, it looks like it started running on both performance cores in parallel, but switched to some of the efficiency cores (probably because the thermal state of the device was getting stressed, which explains we did not achieve anything close to 2× performance):
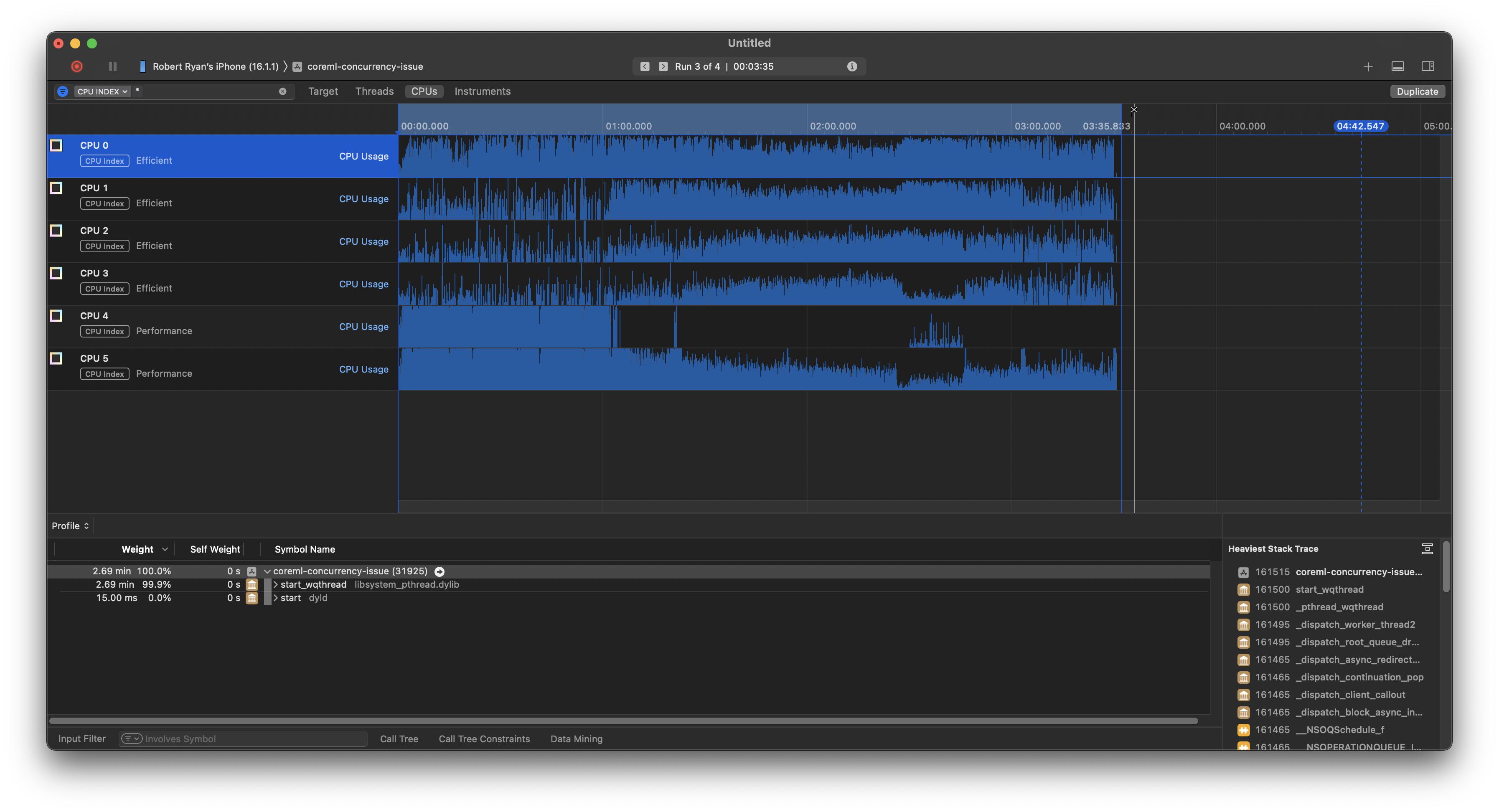
So, when doing CPU-only CoreML calculations, parallel execution can yield significant benefits. That having been said, the CPU-only calculations are much slower than the GPU calculations.
When I switched to .cpuAndGPU, the difference maxConcurrentOperationCount of 1 vs 3 was far less pronounced, taking 45 seconds when allowing three concurrent operations and 50 seconds when executing serially. Here it is running three in parallel:
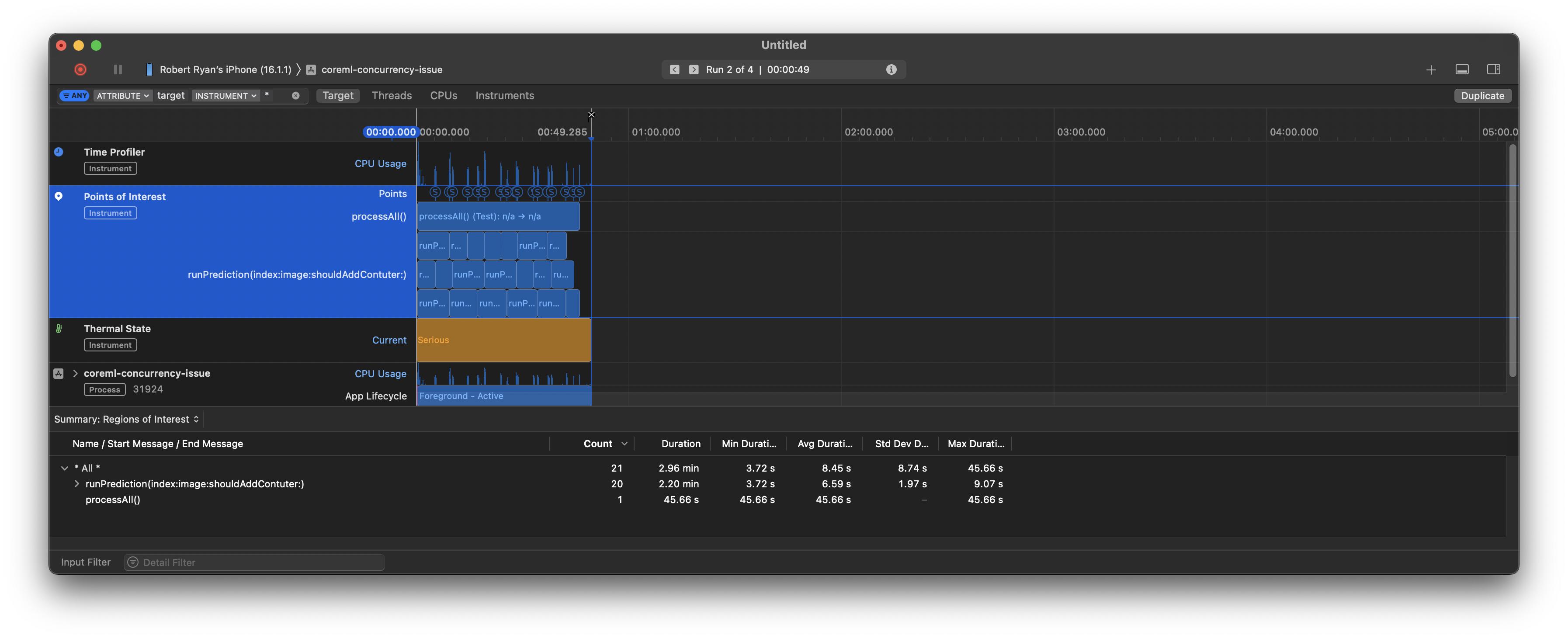
And sequentially:
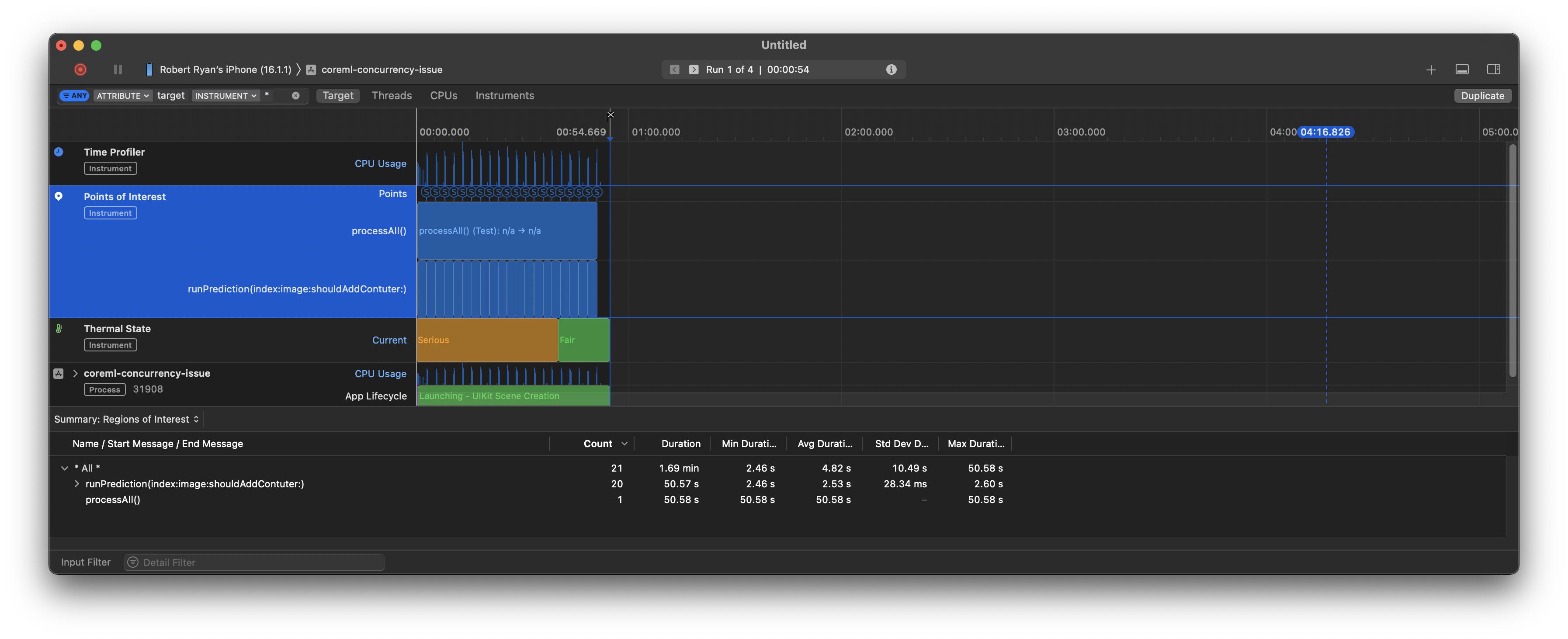
But in contrast to the .cpuOnly scenarios, you can see in the CPU track, that the CPUs are largely idle. Here is the latter with the CPU view to show the details:
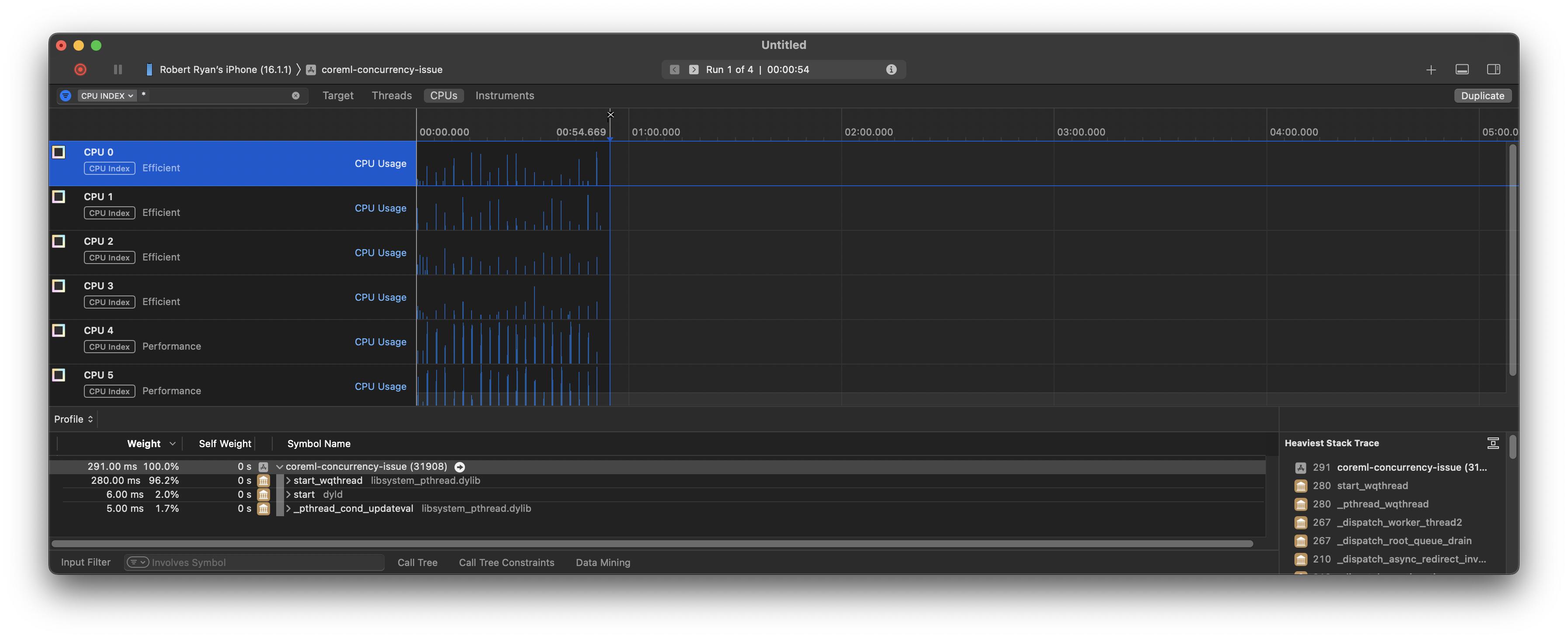
So, one can see that letting them run on multiple CPUs does not achieve much performance gain as this is not CPU-bound, but is obviously constrained by the GPU.
Here is my code for the above. Note, I used OperationQueue as it provides a simple mechanism to control the degree of concurrency (the maxConcurrentOperationCount:
import os.log
private let poi = OSLog(subsystem: "Test", category: .pointsOfInterest)
and
func processAll() {
let parallelTaskCount = 20
let queue = OperationQueue()
queue.maxConcurrentOperationCount = 3 // or try `1`
let id = OSSignpostID(log: poi)
os_signpost(.begin, log: poi, name: #function, signpostID: id)
for i in 0 ..< parallelTaskCount {
queue.addOperation {
let image = UIImage(named: "image.jpg")!
self.runPrediction(index: i, image: image, shouldAddContuter: true)
}
}
queue.addBarrierBlock {
os_signpost(.end, log: poi, name: #function, signpostID: id)
}
}
func runPrediction(index: Int, image: UIImage, shouldAddContuter: Bool = false) {
let id = OSSignpostID(log: poi)
os_signpost(.begin, log: poi, name: #function, signpostID: id, "%d", index)
defer { os_signpost(.end, log: poi, name: #function, signpostID: id, "%d", index) }
let conf = MLModelConfiguration()
conf.computeUnits = .cpuAndGPU // contrast to `.cpuOnly`
conf.allowLowPrecisionAccumulationOnGPU = true
let myModel = try! MyModel(configuration: conf)
let myModelInput = try! MyModelInput(LR_inputWith: image.cgImage!)
// Prediction
let prediction = try! myModel.prediction(input: myModelInput)
os_signpost(.event, log: poi, name: "finished processing", "%d %@", index, prediction.featureNames)
}
Note, above I have focused on CPU usage. You can also use the “Core ML” template in Instruments. E.g. here are the Points of Interest and the CoreML tracks next to each other on my M1 iPad Pro (with maxConcurrencyOperationCount set to 2 to keep it simple):
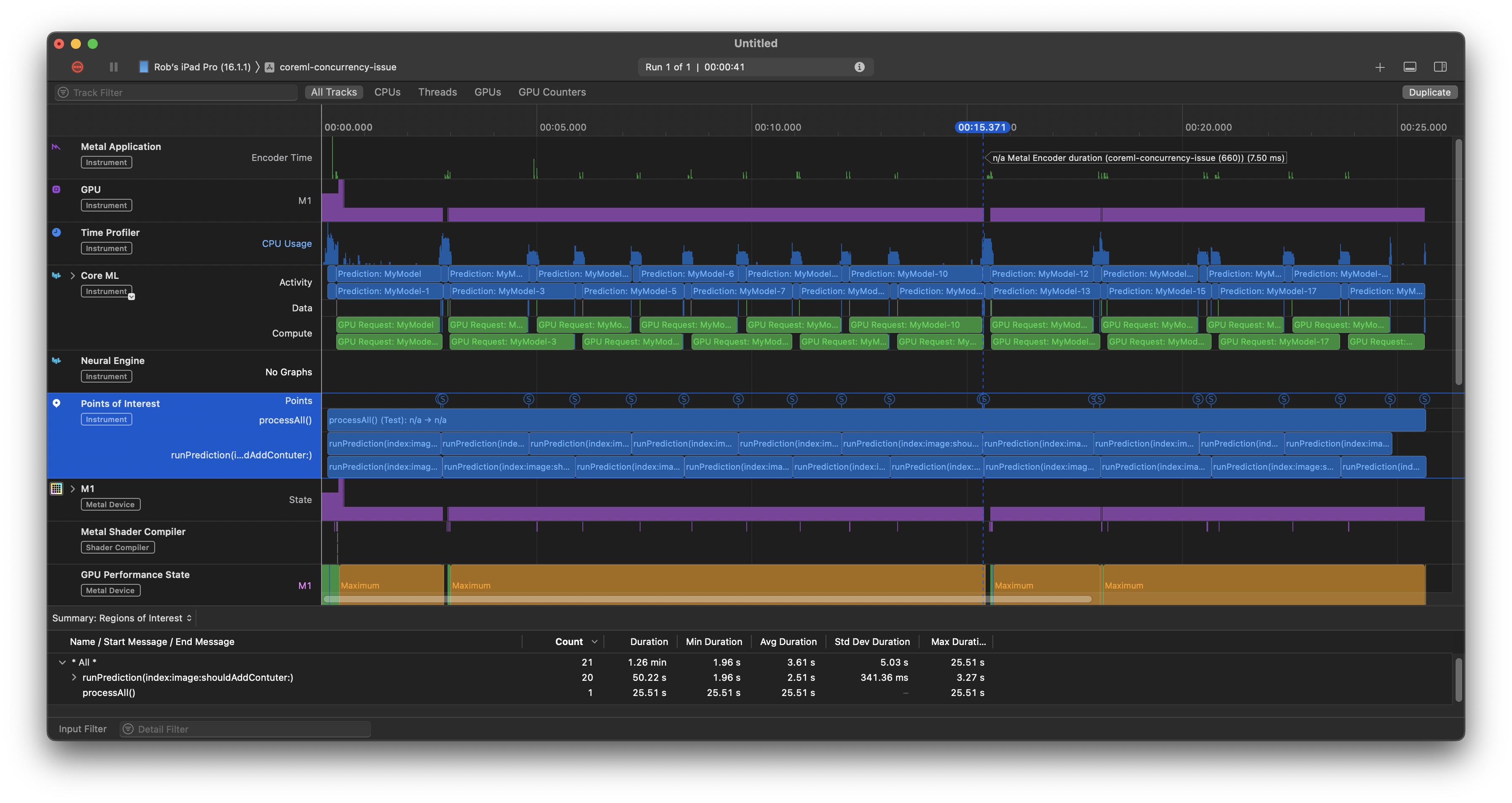
At first glance, it looks like CoreML is processing these in parallel, but if I run it again with maxConcurrencyOperationCount of 1 (i.e., serially), the time for those individual compute tasks is shorter, which suggests that in the parallel scenario that there is some GPU-related contention.
Anyway, in short, you can use Instruments to observe what is going on. And one can achieve significant improvements in performance through parallel processing for CPU-bound tasks only, and anything requiring the GPU or neural engine will be further constrained by that hardware.