I want to make a dataframe from web scrapping this page : 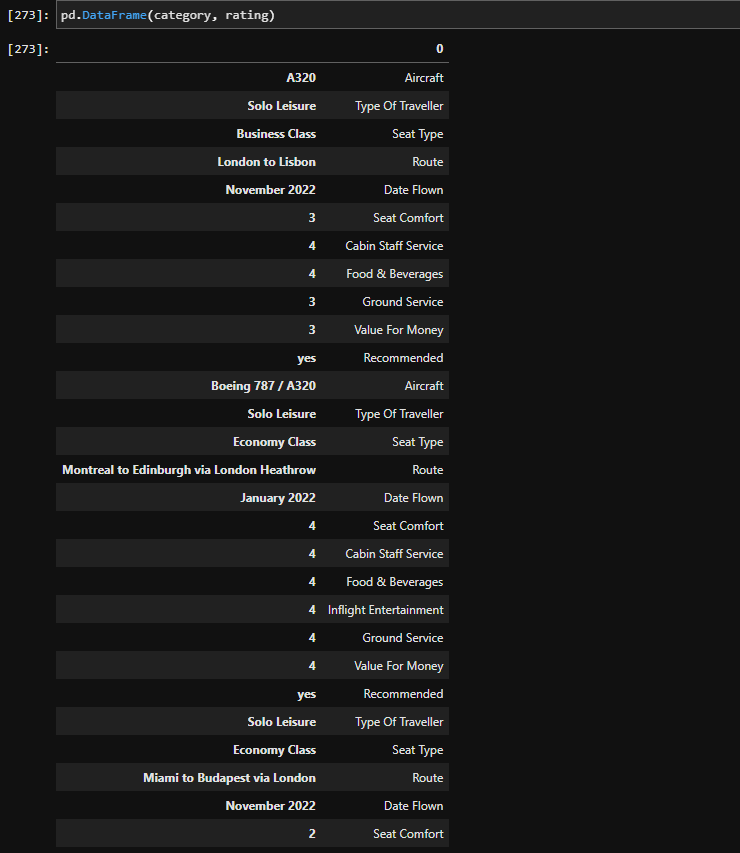
in a simple way, that is what I was asking :
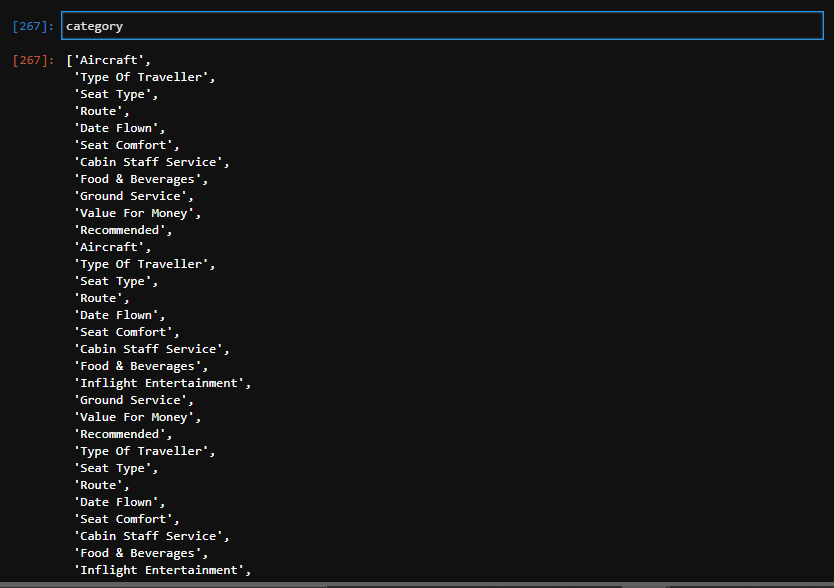
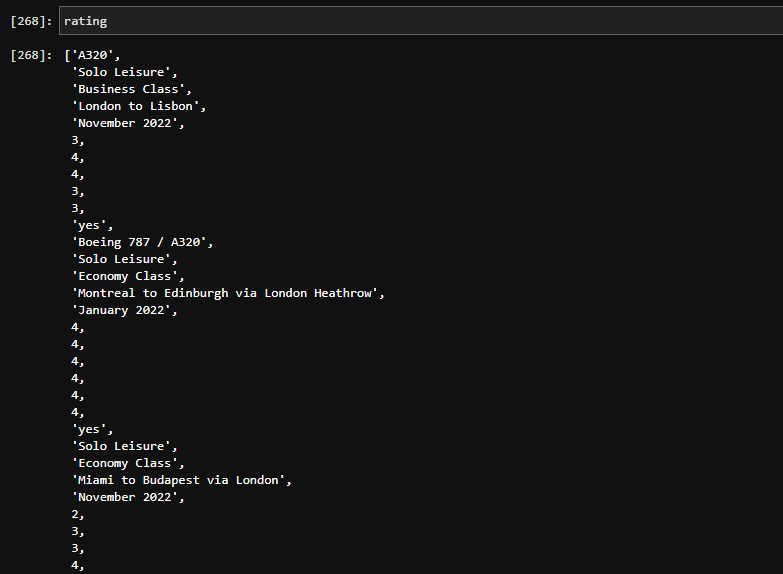
first looping: category is [a, b, c, d, e] rating is [1, 2, 3, 4, 5]
second looping: the category will append with [a, c, e, o, p, q] and rating will append with [9, 8, 7, 6, 5, 4]
so the final data :
category = [a, b, c, d, e, a, c, e, o, p, q]
rating = [1, 2, 3, 4, 5, 9, 8, 7, 6, 5, 4]
output that I want:
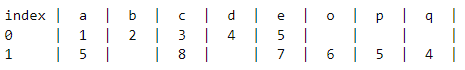
CodePudding user response:
You have the column values, just build the DataFrame
Eg.,
from pandas import DataFrame
category = ["Aircraft", 'Type of Traveller', 'Seat Type']
rating = ['A320', 'Solo', 'Business Class']
# Create the records from both list, using zip and dict calls.
data_dict = dict(zip(category, rating))
# Build the dataframe from the dictionary.
df = DataFrame.from_records(data_dict, columns=category, index=[0])
print(df)
Looks like this. 
CodePudding user response:
Since each review's rating categories start with either "Type of Traveller" or "Aircraft" followed by "Type of Traveller", you could split them up into a list of dictionaries with
cr = [(k, v) for k, v in zip(category, rating)]
si = [i for i, (k, v) in enumerate(cr) if k == 'Type Of Traveller']
si = [(i - 1) if i != 0 and cr[i - 1][0] == 'Aircraft' else i for i in si]
splitCr = [dict(cr[start:end]) for start, end in zip(si, (si[1:] [len(cr)]))]

However, it would be better to build a single list of dictionaries as we scrape [rather than to try to zip and split lists that are not guaranteed to have consistent lengths or contents]
base_url = "https://www.airlinequality.com/airline-reviews/british-airways"
pages = 3 # 5 # 10
page_size = 5 # 1 # 100
revList = []
avgSelRef = {
'rating10': '.rating-10 span[itemprop="ratingValue"]',
'header': 'div.info:has(h1[itemprop="name"])',
'subheader': '.review-count',
'reviewBody': '.skytrax-rating-mob img.skytrax-rating[alt]'
}
rbSel = '.body[id^="anchor"]'
revSelRef = {
'rating10': '.rating-10 span[itemprop="ratingValue"]',
'header': f'{rbSel} h2.text_header',
'subheader': f'{rbSel} h3.text_sub_header',
'reviewBody': f'{rbSel} div[itemprop="reviewBody"]'
}
avgAdded = False
for i in range(1, pages 1):
print("", end=f"Scraping page {i} of {pages} ")
# Create URL to collect links from paginated data
url = f"{base_url}/page/{i}/?sortby=post_date:Desc&pagesize={page_size}"
# Collect HTML data from this page
response = requests.get(url)
if response.status_code != 200:
print(f' -- !ERROR: "{response.raise_for_status()}"" getting {url}')
continue
content = response.content
parsed_content = BeautifulSoup(content, 'html.parser')
avSoups = parsed_content.select('div.review-info')
rvSoups = parsed_content.select(f'article[itemprop="review"]:has({rbSel})')
if avSoups and not avgAdded: rvSoups = avSoups
for r in rvSoups:
isAvg = r.name == 'div'
if isAvg:
rDets = {'reviewId': '[Average]'}
selRef = avgSelRef.items()
avgAdded = True
else:
revId = r.select_one(rbSel).get('id').replace('anchor', '', 1)
selRef = revSelRef.items()
rDets = {'reviewId': revId}
for k, s in selRef:
rdt = r.select_one(s)
if rdt is None: continue
if 'img' in s and s.endswith('[alt]'):
rDets[k] = rdt.get('alt')
else:
rDets[k] = ' '.join(w for w in rdt.get_text(' ').split() if w)
rhSel = 'td.review-rating-header'
rRows = r.select(f'tr:has({rhSel} td:is(.stars, .review-value))')
for rr in rRows:
k = rr.select_one(rhSel).get_text(' ').strip()
k = k.replace(' For ', ' for ').replace(' & ', ' ') # bit of cleanup
if k.endswith('Staff Service'): k = 'Staff Service' # bit of cleanup
if rr.select('td.stars'):
rDets[f'[stars] {k}'] = len(rr.select('td.stars span.star.fill'))
else:
rDets[k] = rr.select_one('td.review-value').get_text().strip()
revList = ([rDets] revList) if isAvg else (revList [rDets])
print(' - ', len(rvSoups), 'reviews --->', len(revList), 'total reviews')
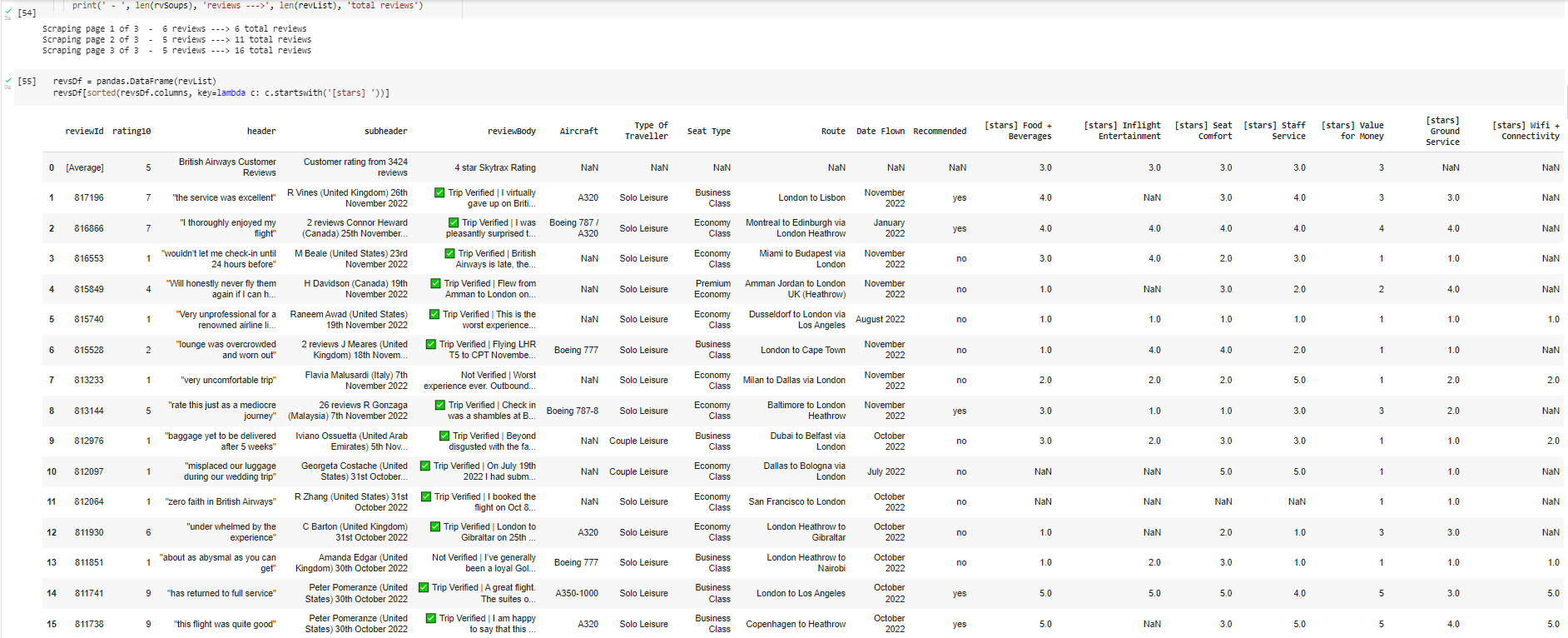
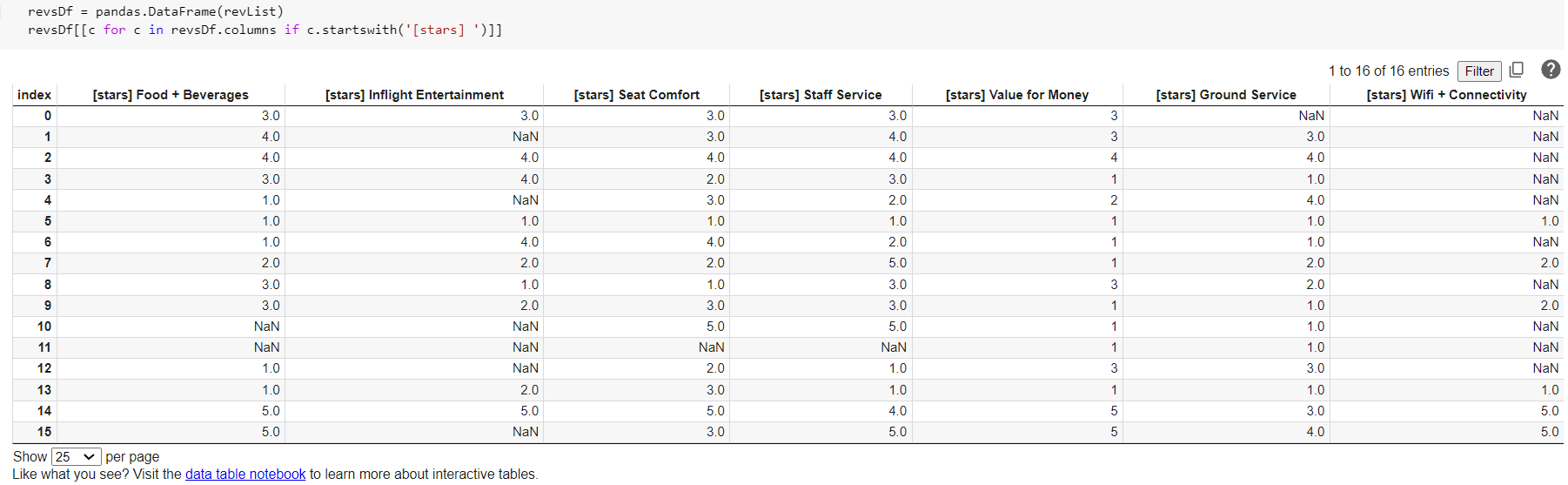
You could also view just the star ratings: