lets say for example we have 2 Dataframes, df1 and df2;
df1 = pd.DataFrame({'id': ['A01', 'A02'],
'Name': ['ABC', 'PQR']})
df2 = pd.DataFrame({'id': ['B05', 'B06'],
'Name': ['XYZ', 'TUV']})
I want to merge the two and label each dataframes, so it appears like this.
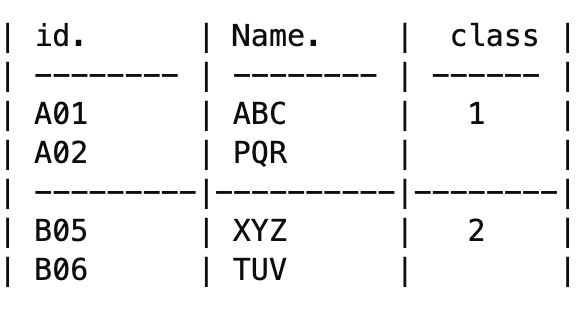
So basically, i want to concatenate two dataframes into a new dataframe and create a third column that labels each of those dataframes. As seen the the table above, you can see that there is a 3rd column named 'class' and the values there are grouping of each dataframes that were merged. The first two above are data for df1 and it was labelled as 1 for all of them. it groups all of them and put them as one.
i'm trying to make sure it doesn't appear like this one below;
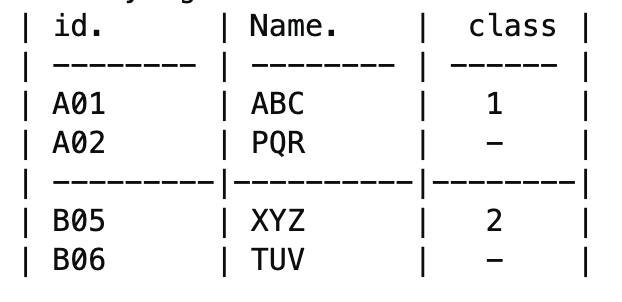
in this case, it's appending for each line.. i prefer to append to the whole DF as single entity as shown in the first table.
This is what I have tried;
df1['class'] = 1
df2['class'] = 2
df_merge = pd.concat([df1,df2])
and i got result like this
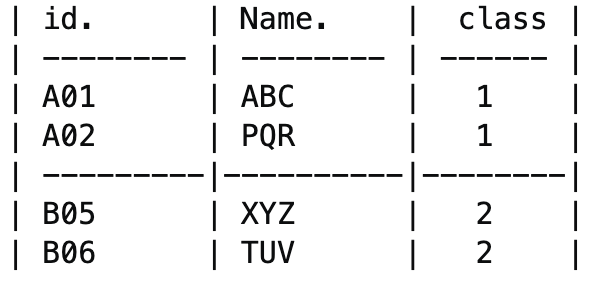
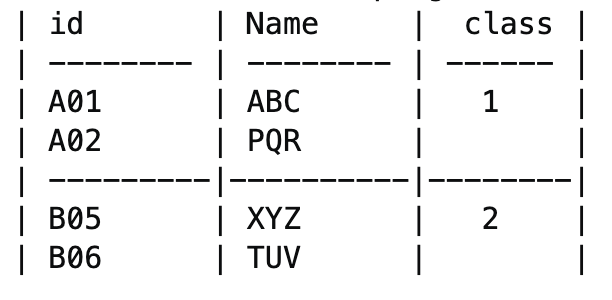
But this is not what I was expecting. I am expecting the result to look like this. Grouping each df as one and add the 3rd column.
CodePudding user response:
You can concat using the keys and names parameters, then reset_index:
(pd.concat([df1, df2], keys=[1, 2], names=['class', None])
.reset_index('class')
)
Output:
class id Name
0 1 A01 ABC
1 1 A02 PQR
0 2 B05 XYZ
1 2 B06 TUV
Or without reset_index to get a MultiIndex:
pd.concat([df1, df2], keys=[1, 2], names=['class', None])
id Name
class
1 0 A01 ABC
1 A02 PQR
2 0 B05 XYZ
1 B06 TUV
hiding the "duplicated" class:
(pd.concat([df1, df2], keys=[1, 2], names=['class', None])
.reset_index('class')
.assign(**{'class': lambda d: d['class'].mask(d['class'].duplicated(), '')})
)
Output:
class id Name
0 1 A01 ABC
1 A02 PQR
0 2 B05 XYZ
1 B06 TUV