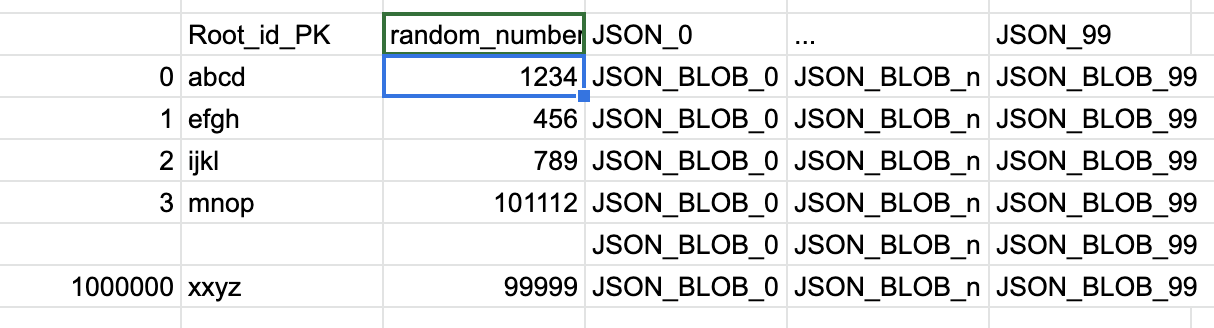
So I have the following dataframe:
The JSON blobs all look something like this:
{"id":"dddd1", "random_number":"77777"}
What I want my dataframe to look like is something like this:

Basically what I need is to get a way to iterate and normalize all the JSON blob columns and put them back in the dataframe in the proper rows (0-99). I have tried the following:
pd.json_normalize(data_frame.iloc[:, JSON_0,JSON_99])
I get the following error:
IndexingError: Too many indexers
I could go through and normalize each JSON_BLOB column individually however that is inefficient, I cant think of a proper way to do this via a Lambda function or for loop because of the JSON blob. The for loop I wrote gives me the same error:
array=[]
for app in data_frame.iloc[:, JSON_0,JSON_99]:
data = {
'id': data['id']
}
array.append(data)
test= pd.DataFrame(array)
IndexingError: Too many indexers
Also some of the JSON_Blobs have NAN values
Any suggestions would be great.
CodePudding user response:
Can you try this:
normalized = pd.concat([df[i].apply(pd.Series) for i in df.iloc[:,2:]],axis=1) #2 is the position number of JSON_0.
final = pd.concat([df[['Root_id_PK','random_number']],normalized],axis=1)
if you want the column names as in the question:
normalized = pd.concat([df[i].apply(pd.Series).rename(columns={'id':'id_from_{}'.format(i),'random_number':'random_number_from_{}'.format(i)}) for i in df.iloc[:,2:]],axis=1)
final = pd.concat([df[['Root_id_PK','random_number']],normalized],axis=1)