I have a MSSQL database table Events. I am worried that performance could be improved.
EventId LocationId Start End Quantity Price Currency
1 4 2022-08-31 22:00:00.0000000 02:00 2022-08-31 23:00:00.0000000 02:00 7.50000 2.0 EUR
2 2 2022-04-04 19:00:00.0000000 01:00 2022-04-04 20:00:00.0000000 01:00 1.50000 7.5 EUR
3 2 2022-04-04 19:00:00.0000000 01:00 2022-04-04 20:00:00.0000000 01:00 4.00000 8.2 EUR
I already have the following index:
CREATE NONCLUSTERED INDEX [IDX__Events__Location_Start_End] on [Events]
(
[LocationId] asc,
[Start] asc,
[End] asc
)
But Azure suggests that I create this index (medium impact):
CREATE NONCLUSTERED INDEX [IDX__Events__Location_End] ON [dbo].[Events] ([LocationId], [End]) INCLUDE ([Currency], [Price], [Quantity], [Start]) WITH (ONLINE = ON)
Hint: I do a lot of queries where I select Events greater than a start time and less than an end time.
Why is this extra index useful? Should I change my first index instead?
EDIT:
I run this code (EF Core) very often:
var relevantEvents = await _events.Where($@"
[{nameof(Events.LocationId)}] = @locationId
and [{nameof(Events.End)}] > @start
and [{nameof(Events.Start)}] < @end
", args);
Besides that, I upsert to the table often as well.
CodePudding user response:
If you always do queries of the form shown at the end of your question with an equality predicate on LocationId and an inequality predicate on both End and Start then both LocationId, End and LocationId, Start would be viable indexing choices.
Note there is no benefit of adding the third column in as a key column because it will only be able to do a range seek for one or the other of them but the other one should be added as an included column.
My suspicion is that for typical scenarios LocationId, Start will generally involve reading more rows in the range seek than LocationId, End would (as the table accumulates years worth of data Start < @end will still need to read all the old rows from years ago).
The reason your existing index might not be being used and it feels moved to suggest an additional one is due to the INCLUDE ([Currency], [Price], [Quantity]) in the suggested one. If you add these included columns to your existing one you may well see the recommendation go away but you should consider which of LocationId, End and LocationId, Start will typically be able to narrow down the rows better (see "Numbers of rows read" in the execution plan).
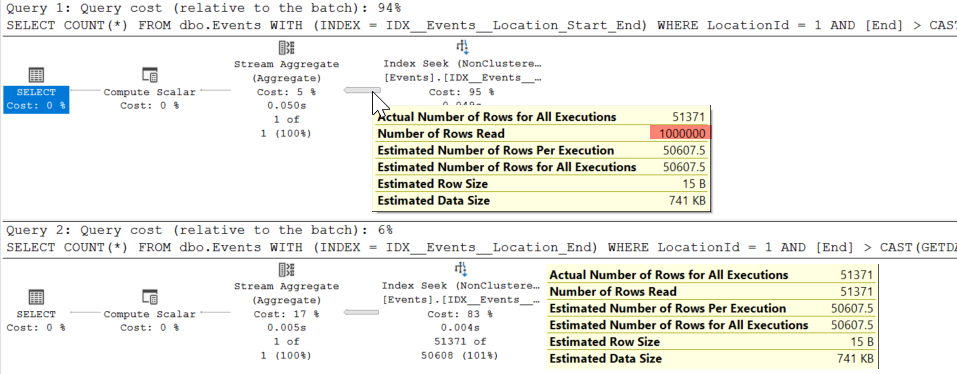
CREATE TABLE dbo.Events
(
EventId INT IDENTITY PRIMARY KEY,
LocationId INT,
Start DATETIME2,
[End] DATETIME2,
Quantity DECIMAL(10,6),
Price DECIMAL(10,2),
Currency CHAR(3),
INDEX IDX__Events__Location_Start_End(LocationId, Start, [End]),
INDEX IDX__Events__Location_End(LocationId, [End]) INCLUDE (Start)
)
INSERT INTO dbo.Events
(LocationId, Start,[End], Quantity, Price,Currency)
SELECT LocationId = 1,
Start = DATEADD(SECOND, -Num, GETDATE()),
[End] = DATEADD(SECOND, 60-Num, GETDATE()),
Qty = 7.5,
Price = 2,
Currency = 'EUR'
FROM
(
SELECT TOP 1000000 Num = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM sys.all_columns c1, sys.all_columns c2
) Nums
DECLARE @Start DATE = GETDATE(), @End DATE = DATEADD(DAY, 1, GETDATE())
SELECT COUNT(*)
FROM dbo.Events WITH (INDEX = IDX__Events__Location_Start_End)
WHERE LocationId = 1 AND [End] > @Start AND Start < @End
OPTION (RECOMPILE)
SELECT COUNT(*)
FROM dbo.Events WITH (INDEX = IDX__Events__Location_End)
WHERE LocationId = 1 AND [End] > @Start AND Start < @End
OPTION (RECOMPILE)
CodePudding user response:
It appears that the index suggested by Azure (IDX__Events__Location_End) would be useful for improving the performance of queries that filter events by location and end time. This index would include the location and end time columns, as well as the currency, price, quantity, and start time columns. This would allow the database engine to quickly look up and return events that match the specified criteria without having to scan the entire table.
As for your existing index (IDX__Events__Location_Start_End), it would be useful for improving the performance of queries that filter events by location, start time, and end time. However, since your code only filters events by location and end time, this index may not be as useful as the one suggested by Azure.
In terms of which index to use, it ultimately depends on the specific queries and workloads that your application uses. If your queries and workloads primarily involve filtering events by location and end time, then it would make sense to use the index suggested by Azure (IDX__Events__Location_End). If, on the other hand, your queries and workloads primarily involve filtering events by location, start time, and end time, then it would make sense to use your existing index (IDX__Events__Location_Start_End).
It is also worth noting that having multiple indexes can improve query performance, but it can also impact the performance of insert, update, and delete operations. Therefore, it is important to carefully consider the trade-offs and decide which indexes are most appropriate for your specific workloads and performance requirements.