I have treatment and control groups stored separately in two dfs. I am interested in presenting two variables 1) sentiment and by 2) month_year across for the two groups in the same graph. Each row in the df represents a tweet followed by the predicted sentiment and the month_year where it was written. For example, in the control group, the data looks as follows:
tweet sentiment month_year
xyz negative. March_2022
xyz positive. March_2022
xyz neutral. March_2022
xyz negative. April_2022
And similarly, the treatment group df are structured as follows:
tweet sentiment month_year
xyz negative. March_2022
xyz positive. March_2022
xyz positive. March_2022
xyz positive. April_2022
And I am interesting in count the share of negative tweets per month across time and between the two groups.
Here is my attempt at creating the graph for one group. However, I am interested in generating the same indicator below but for both groups at once, so that I can present them in the same graph where I compare the trends for both groups throughout time.
Create a variable counting 1-negative sentiment posts and 2-their share per month
sentiment_monthly <- control_group %>%
group_by(month_year) |>
#group_by(treatment_details) |>
summarise(sentiment_count = n(),
negative_count = sum(sentiment_human_coded == "negative"),
negative_share = negative_count/sentiment_count * 100)
Here is a data example of the "sentiment_monthly" df:
dput(sentiment_monthly[1:5],)
output:
structure(list(month_year = structure(c(2011.16666666667, 2011.25,
2011.41666666667, 2011.75, 2011.83333333333, 2011.91666666667,
2012.08333333333, 2012.16666666667, 2012.25, 2012.33333333333
), class = "yearmon"), sentiment_count = c(272L, 62L, 64L, 434L,
111L, 59L, 72L, 144L, 43L, 17L), negative_count = c(27L, 23L,
47L, 317L, 79L, 27L, 25L, 78L, 27L, 3L), negative_share = c(9.92647058823529,
37.0967741935484, 73.4375, 73.0414746543779, 71.1711711711712,
45.7627118644068, 34.7222222222222, 54.1666666666667, 62.7906976744186,
17.6470588235294), year = c(2011, 2011, 2011, 2011, 2011, 2011,
2012, 2012, 2012, 2012)), row.names = c(NA, -10L), class = c("tbl_df",
"tbl", "data.frame"))
and then the viz:
Visualizing negative sentiment by month
ggplot(data = sentiment_monthly, aes(x = as.Date(month_year), y = negative_share))
geom_bar(stat = "identity", fill = "#FF6666", position=position_dodge())
scale_fill_grey()
scale_x_date(date_breaks = "1 month", date_labels = "%b %Y")
theme(plot.title = element_text(size = 18, face = "bold"))
theme_bw()
theme(axis.title.x=element_blank(),
axis.ticks.x=element_blank()) # remove x-axis label
theme(plot.title = element_text(size = 5, face = "bold"),
axis.text.x = element_text(angle = 90, vjust = 0.5))
output: [![enter image description here][1]][1]
Based on the useful advice below, I did this, which works well!
control_graph |> select(month_year,group, negative_share) |>
filter(group == "control")
treatment_graph |> select(month_year,group, negative_share) |>
filter(group == "treatment")
control_graph |>
bind_rows(treatment_graph) |>
ggplot(aes(x = as.Date(month_year), y = negative_share, fill = group))
geom_bar(stat = "identity", position=position_dodge())
CodePudding user response:
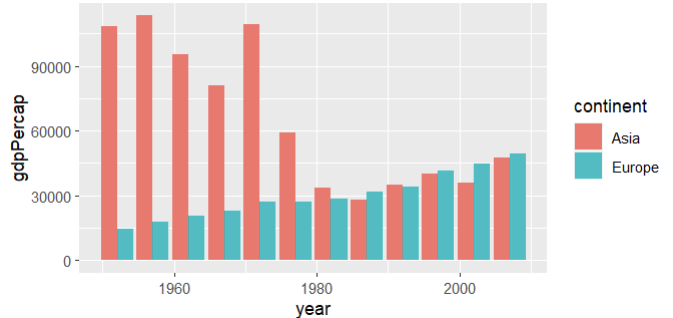
You could try to bring the two dataframes in a similar struture, bind_rows and create a grouped bar chart like this:
library(tidyverse)
control <- gapminder::gapminder |> select(year,continent, gdpPercap) |>
filter(continent == "Asia")
treatment <- gapminder::gapminder |> select(year,continent, gdpPercap) |>
filter(continent == "Europe")
control |>
bind_rows(treatment) |>
ggplot(aes(x=year, y = gdpPercap, fill = continent))
geom_bar(stat = "identity", position=position_dodge())