I have multiple dict in a list and I want loop through each dict and flatten the file. When I run this code its giving me the 'NoneType' object is not subscriptable error. And the custom fields in the below json will be having many other fields as well
import asana
import json
import pandas as pd
from tabulate import tabulate
client = asana.Client.access_token('Access_token')
portfolio_items = client.portfolios.get_items_for_portfolio('Portfolio_id',
opt_fields = ['gid'],
opt_pretty=True
)
Project_list = pd.DataFrame(portfolio_items)
project_details = []
for (index, row_data) in Project_list.iterrows():
project_object=client.projects.get_project(project_gid=row_data["gid"],
opt_fields = [
'gid','name','start_on','archived','completed',
'completed_at','created_at','current_status.color','current_status.created_at',
'current_status.modified_at','custom_fields.name','custom_fields.display_value'
],opt_pretty= True
)
project_details.append(project_object)
Flatten_file = pd.DataFrame()
if project_details is not None:
for project in project_details:
flatten_json_file1 = pd.json_normalize(project,record_path =['custom_fields'],
meta=['gid', 'name','start_on','archived','completed','completed_at','created_at', ['current_status', 'Color'],['current_status', 'created_at'],['current_status', 'modified_at']],
errors='ignore',
meta_prefix='meta-',
record_prefix='custom-'
)
Flatten_file.append(flatten_json_file1)
print(Flatten_file)
Project_details list will be consisting of info like this
[
{
"gid": "324673284",
"archived": false,
"completed": false,
"completed_at": null,
"created_at": "2022-10-25T18:20:01.358Z",
"current_status": null,
"custom_fields": [
{
"gid": "279970056320993",
"name": "Priority",
"display_value": null
},
{
"gid": "1202467628629378",
"name": "Size ( PXT-BI )",
"display_value": "Large"
},
],
"name": "Hawkeye Anecdote Escalation Model",
"start_on": null
},
{
"gid": "3878432832",
"archived": false,
"completed": false,
"completed_at": null,
"created_at": "2022-12-13T01:24:45.658Z",
"current_status": null,
"custom_fields": [
{
"gid": "1202467628629378",
"name": "Size ( PXT-BI )",
"display_value": "Small"
},
{
"gid": "1202475692803938",
"name": "Project Type ( PXT-BI )",
"display_value": null
},
{
"gid": "1202537017669433",
"name": "Tracks ( PXT-BI )",
"display_value": "Strategic Programs"
},
{
"gid": "1202467628625109",
"name": "Scrum Stage ( PXT-BI )",
"display_value": "In Progress"
}
],
"name": "Create Data Connection For New Conversions Dashboard",
"start_on": null
}
]
And My desired Output should be looking like
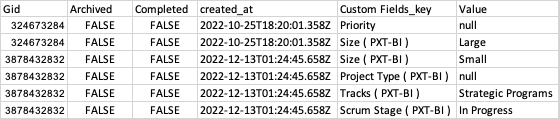
CodePudding user response:
Preparing the data:
Project_details = *the array above you inserted*
Project_details
It returns your array of dicts. Then you use list comprehension:
dataset = [
[proj['gid'], proj['archived'], proj['completed'], proj['created_at'], custom_field['name'], custom_field['display_value']]
for proj in Project_details
for custom_field in proj['custom_fields']]
dataset
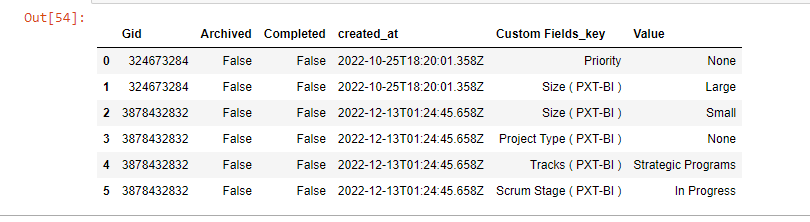
Then you built 1 row with the goal data. Let's format dataframe:
col = ['Gid', 'Archived', 'Completed', 'created_at', 'Custom Fields_key', 'Value']
df = pd.DataFrame(data = dataset, columns = col)
df
The output showed by jupyter:
CodePudding user response:
Using JSON.parsify you can read your json file as a dictionary. Then I suggest you create a new pandas Dataframe from the select keys you want from the dictionary, and then save that Dataframe into a CSV file. Hope this helps!