I have two dataframes, one is the score with a given date,
date score
2022-12-01 0.28
2022-12-01 0.12
2022-12-01 0.36
2022-12-01 0.42
2022-12-01 0.33
2022-12-02 0.15
2022-12-03 0.23
2022-12-03 0.25
Another dateframe is score bins,
breakpoints
0.1
0.2
0.3
0.4
0.5
The breakpoint 0.1 means any values less or equals to 0.1.
How do I create a dataframe that group the data with this known bins by date? I tried to use numpy.histogram which the aggregate function works good but doesn't know how to group it by date.
My expected output will be like,
breakpoints 2022-12-01 2022-12-02 2022-12-03 ...
0.1 0 0 0
0.2 1 1 0
0.3 1 0 2
0.4 2 0 0
... ... ... ...
CodePudding user response:
You can use the pandas.cut() function to bin your data by date.
df['binned'] = pd.cut(df['score'], bins=breakpoints, include_lowest=True)
Then use the groupby function to group by date and bins:
df.groupby(['date','binned']).count()
This will give you the number of scores in each bin, per date.
CodePudding user response:
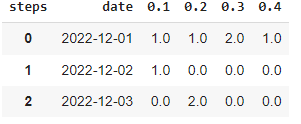
step1) Create a new column for the steps:
import numpy as np
df['steps'] = np.round(np.floor((df.score)/0.1)*0.1, 1)
step2) Do the group by and rename the aggregate column:
out_df = (df[['date', 'steps']]).groupby(['date', 'steps']).size().reset_index().rename(columns={0:'count'})
step3) use the pivot function and replace the None values:
out_df = out_df.pivot(index='date', columns='steps', values='count').reset_index().fillna(0)
the final result looks like this: