I'm trying to break a certain script into couple of functions, and I ended up with an error of "AttributeError: ResultSet object has no attribute 'get'. You're probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?"
I tried to find how to fix it, but I end up in the same place. This is the original script:
#setting query
query = "stroke"
#handleing white spaces
search = query.replace(' ', ' ')
#setting results
results = 20
#setting the full url
url = (f"https://www.google.com/search?q={search}&num={results}")
#empty list for links
link_list = []
#scraping google
requests_results = requests.get(url)
soup_link = bs(requests_results.content, "html.parser")
links = soup_link.find_all("a")
#for each link in soup checking
for link in links:
link_href = link.get('href')
if "url?q=" in link_href and not "webcache" in link_href:
title = link.find_all('h3')
if len(title) > 0:
full_link = link.get('href').split("?q=")[1].split("&sa=U")[0]
link_list.append(full_link)
print(full_link)
print(title[0].getText())
print("------")
This is the output:
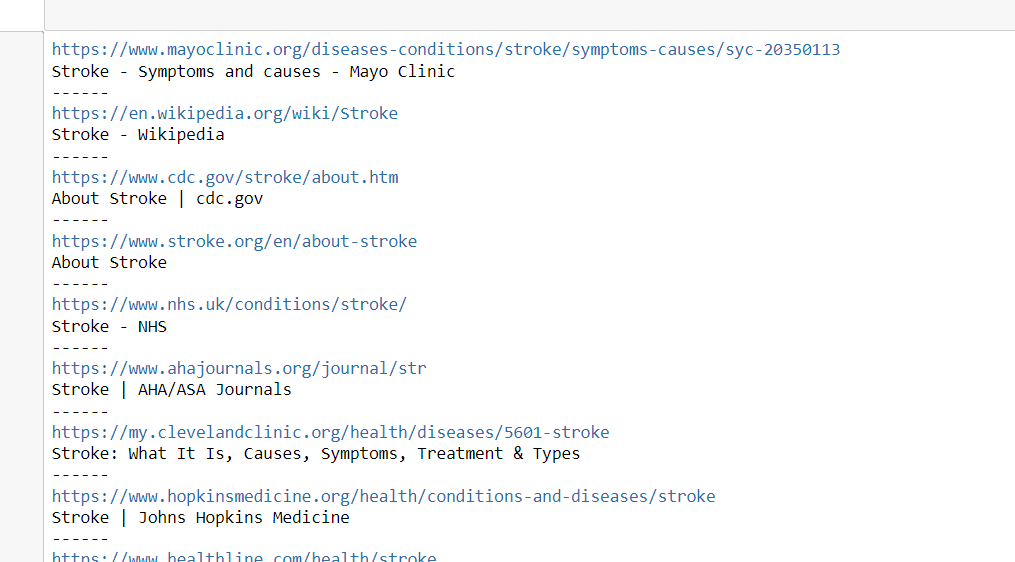
It runs perfectly. The idea is to take the query, change it to a list of phrases I want, and getting the same end result formation, for each query.
So I broke the code to couple of functions, and the last one gives me the error. Below is the code:
query_list = ['Coronary artery disease','Stroke','Diabetes mellitus','Alzheimer','Lower respiratory infections',\
'Lung cancer','Cirrhosis']
query_list
First function:
def getting_links_func (queries):
url_list = []
#setting query
func_queries = queries
#setting results
results = 10
for query in func_queries:
#handleing white spaces
search = query.replace(' ', ' ')
#setting the full url
url = (f"https://www.google.com/search?q={search}&num={results}")
#update list with links
url_list.append(url)
return url_list
output:
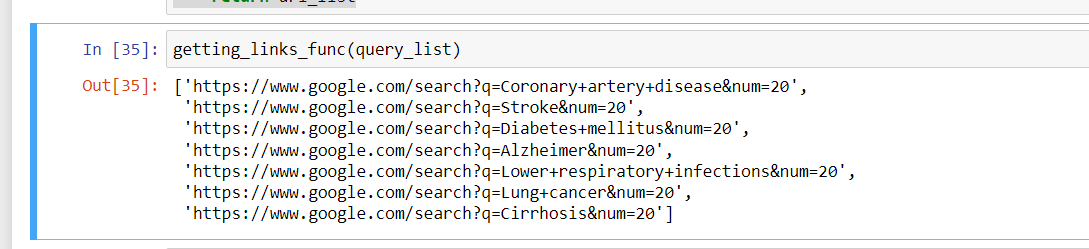
second function:
def links_soup_func (url_list):
soup_list = []
for url in url_list:
#scraping google
requests_results = requests.get(url)
soup_link = bs(requests_results.content, "html.parser")
links = soup_link.find_all("a")
soup_list.append(links)
return soup_list
seems to work well:
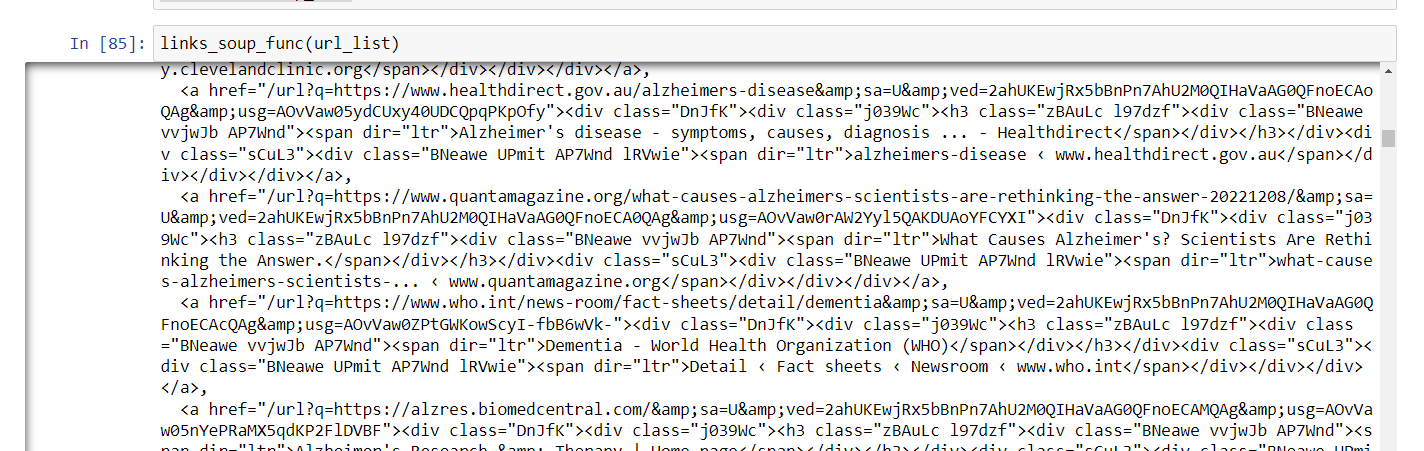
the third function is the naughty one:
def urls_from_soup_func (soup_list):
#for each soup getting the links in the search page
for soup in soup_list:
link_href = soup.get('href')
if "url?q=" in link_href and not "webcache" in link_href:
title = soup.find_all('h3')
if len(title) > 0:
full_link = soup.get('href').split("?q=")[1].split("&sa=U")[0]
link_list.append(full_link)
print(full_link)
print(title[0].getText())
print("------")
here I'm getting the find or find all error. I tried playing around, breaking the for loop and checking just for one item, but I keep getting to the same issue.
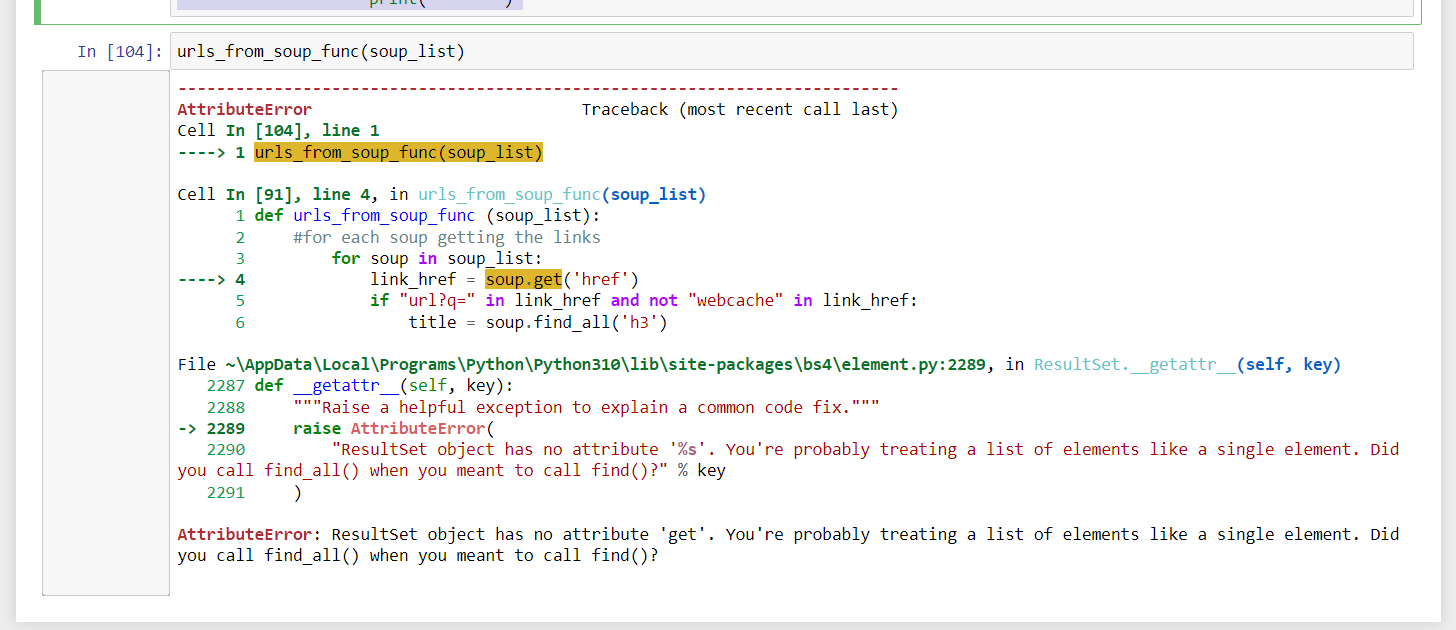
I hope I explained myself well. Thanks for the help
CodePudding user response:
The error is pretty clear. You are appending the ResultSet object to your list, instead of extending it with single <a> elements.
# what you are doing is this
a = [1, 2]
b = [3, 4]
a.append(b)
print(a) # [1, 2, [3, 4]]
# you should be doing this
a.extend(b)
print(a) # [1, 2, 3, 4]
Below change should solve your problem.
soup_list.extend(links)