The data looks like this
schema = StructType([StructField("ID",StringType(),True), \
StructField("Priority", IntegerType(),True)])
data = spark.createDataFrame([("A",1),("B",1),("B",2),("C",2),("C",3),("D",3)],schema)

Problem statement: For each priority, the ID has to be compared with all the ID's of previous priorities.
For example, priority 2 to be compared with IDs of priority 1, priority 3 to be compared with IDs of priority 1 and 2, and so on.
Step 1: Creating new_data by filtering priority 1
new_data = data.filter(col('Priority') == 1)
Step 2: Subtracting the next priority with the new data and then appending the result with the new data.
for i in range(2,4):
x = data.filter(col('Priority') == i).select('ID')
x = x.subtract(new_data.select('ID'))
x = x.withColumn('Priority',F.lit(i))
new_data = new_data.union(x)
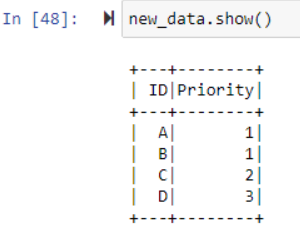
The final new_data is the desired outcome. But the problem is that with big data, this approach is much slower as the size of new data increases each iteration.
Is there a faster approach to this method? Kindly help.
CodePudding user response:
IIUC you want the highest priority (which is the lowest value) per ID. This can be done simply by grouping by id and selecting min(priority).
data.groupby('ID').min('Priority').show()
--- -------------
| ID|min(Priority)|
--- -------------
| A| 1|
| B| 1|
| C| 2|
| D| 3|
--- -------------
CodePudding user response:
The faster approach is to make a window partitioned by 'ID' (so each of them checks individually) and ordered by 'Priority'. Then for each row check what is the min priority seen for that 'ID'. If the min priority is equal to priority of that row it means there is no lower priority for that 'ID' so it would be in your final output table
window = W.partitionBy('ID').orderBy('Priority')
(
data
.withColumn('minPriority', F.min('Priority').over(window))
.filter(F.col('Priority') == F.col('minPriority'))
.drop('minPriority')
).show()