I have a data frame containing one row:
df_1D = pd.DataFrame({'Day1':[5],
'Day2':[6],
'Day3':[7],
'ID':['AB12'],
'Country':['US'],
'Destination_A':['Miami'],
'Destination_B':['New York'],
'Destination_C':['Chicago'],
'First_Agent':['Jim'],
'Second_Agent':['Ron'],
'Third_Agent':['Cynthia']},
)
Day1 Day2 Day3 ID ... Destination_C First_Agent Second_Agent Third_Agent
0 5 6 7 AB12 ... Chicago Jim Ron Cynthia
I'm wondering if there's an easy way, to transform it into a dataframe with three rows as shown here:
Day ID Country Destination Agent
0 5 AB12 US Miami Jim
1 6 AB12 US New York Ron
2 7 AB12 US Chicago Cynthia
CodePudding user response:
One option using reshaping, which only requires to know the final columns:
# define final columns
cols = ['Day', 'ID', 'Destination', 'Country', 'Agent']
# the part below is automatic
# ------
# extract the keywords
pattern = f"({'|'.join(cols)})"
new = df_1D.columns.str.extract(pattern)[0]
# and reshape
out = (df_1D
.set_axis(pd.MultiIndex.from_arrays([new, new.groupby(new).cumcount()]), axis=1)
.loc[0].unstack(0).ffill()[cols]
)
Output:
Day ID Destination Country Agent
0 5 AB12 Miami US Jim
1 6 AB12 New York US Ron
2 7 AB12 Chicago US Cynthia
alternative defining idx/cols separately
idx = ['ID', 'Country']
cols = ['Day', 'Destination', 'Agent']
df2 = df_1D.set_index(idx)
pattern = f"({'|'.join(cols)})"
new = df2.columns.str.extract(pattern)[0]
out = (df2
.set_axis(pd.MultiIndex.from_arrays([new, new.groupby(new).cumcount().astype(str)],
names=[None, None]),
axis=1)
.stack().reset_index(idx)
)
CodePudding user response:
clomuns_day=[col for col in df_1D if col.startswith('Day')]
clomuns_dest=[col for col in df_1D if col.startswith('Destination')]
clomuns_agent=[col for col in df_1D if 'Agent'in col]
new_df=pd.DataFrame()
new_df['Day']=df_1D[clomuns_day].values.tolist()[0]
new_df['ID']= list(df_1D['ID'])*len(new_df)
new_df['Country']= list(df_1D['Country'])*len(new_df)
new_df['Destination']=df_1D[clomuns_dest].values.tolist()[0]
new_df['Agent']=df_1D[clomuns_agent].values.tolist()[0]
Out:
Day ID Country Destination Agent
0 5 AB12 US Miami Jim
1 6 AB12 US New York Ron
2 7 AB12 US Chicago Cynthia
you can use it whatever destination is repeat
CodePudding user response:
Have you tried to pivot it with .pivot function? 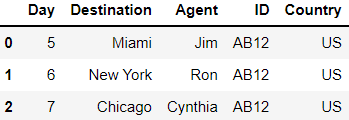
Hope this help.
CodePudding user response:
One option is with pivot_longer from pyjanitor, where for this case, you pass a list of regexes to names_pattern, and the new column names to names_to:
# pip install pyjanitor
import janitor
import pandas as pd
(df_1D
.pivot_longer(
index=['ID','Country'],
names_to = ['Day','Destination','Agent'],
names_pattern=['Day','Destination','Agent'])
)
ID Country Day Destination Agent
0 AB12 US 5 Miami Jim
1 AB12 US 6 New York Ron
2 AB12 US 7 Chicago Cynthia