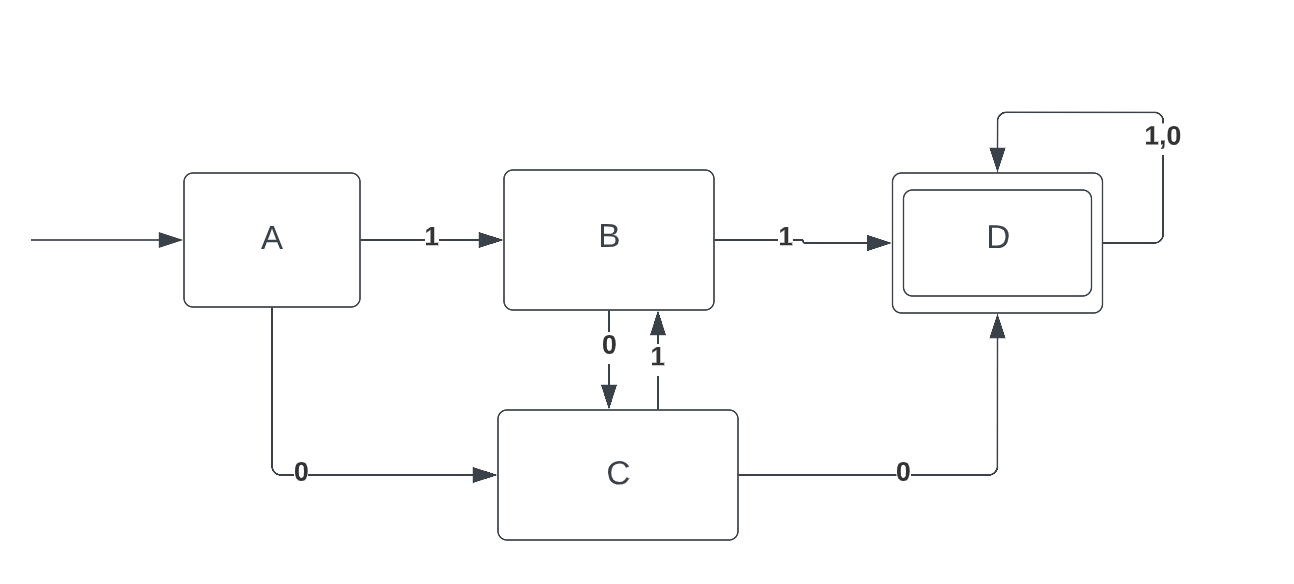
Consider the following state diagram which accepts the alphabet {0,1} and accepts if the input string has two consecutive 0's or 1's:
01001 --> Accept
101 --> Reject
How would I write the production rules to show this? Is it just:
D -> C0 | B1 | D0 | D1
C -> A0 | B0
B -> A1 | C1
And if so, how would the terminals (0,1) be differentiated from the states (A,B,C) ? And should the state go before or after the input? That is, should it be A1 or 1A for example?
CodePudding user response:
The grammar you suggest has no A: it's not a non-terminal because it has no production rules, and it's not a terminal because it's not present in the input. You could make that work by writing, for example, C → 0 | B 0, but a more general solution is to make A into a non-terminal using an ε-rule: A → ε and then
C → A 0 | B 0.
B0 is misleading, because it looks like a single thing. But it's two grammatical symbols, a non-terminal (B) and a terminal 0.
With those modifications, your grammar is fine. It's a left linear grammar; a right linear grammar can also be constructed from the FSA by considering in-transitions rather than out-transitions. In this version, the epsilon production corresponds to final states rather than initial states.
A → 1 B | 0 C
B → 0 C | 1 D
C → 1 B | 0 D
D → 0 D | 1 D | ε
If it's not obvious why the FSM corresponds to these two grammars, it's probably worth grabbing a pad of paper and constructing a derivation with each grammar for a few sample sentences. Compare the derivations you produce with the progress through the FSM for the same input.