Say I have a df like
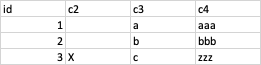
and I want a df like this
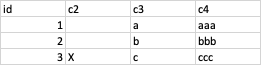
How would I do this in python or R? This would be so easy in excel with a simple if statement, for example: c5 =IF(c2 = "X", "ccc", c4).
I thought this would be simple in R too, but I tried df <- df %>% mutate(c4 = ifelse(c2 = 'X', paste(c3, c3, c3), c4)), and it fills all the other values with NA's:
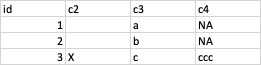
Why is this happening and how would I fix it?
Ideally though, I'd like to do this in python. I've tried dfply's mutate and ifelse similarly to the above, and using pandas loc function, but neither have worked.
This feels like it should be really simple - is there something obvious that I'm missing?
CodePudding user response:
We may need strrep in R
library(dplyr)
df %>%
mutate(c4 = ifelse(c2 %in% "X", strrep(c3, nchar(c4)), c4))
-output
id c2 c3 c4
1 1 a aaa
2 2 b bbb
3 3 X c ccc
data
df <- structure(list(id = 1:3, c2 = c("", "", "X"), c3 = c("a", "b",
"c"), c4 = c("aaa", "bbb", "zzz")), class = "data.frame", row.names = c(NA,
-3L))
CodePudding user response:
df.c4.where(df.c2.ne("X"), other=df.c3 * 3)
This reads as
"for c4 column: where the c2 values are not equal to "X", keep them as is; otherwise, put the 3-times repeated c3 values".
Example run:
In [182]: df
Out[182]:
id c2 c3 c4
0 1 a aaa
1 2 b bbb
2 3 X c zzz
In [183]: df.c4 = df.c4.where(df.c2.ne("X"), other=df.c3 * 3)
In [184]: df
Out[184]:
id c2 c3 c4
0 1 a aaa
1 2 b bbb
2 3 X c ccc
CodePudding user response:
I think you can just do in pandas:
m = df['c2'] == 'X'
df.loc[m, 'c4'] = df.loc[m, 'c3'].str.repeat(3)
Look for rows whose 'c2' is 'X' and locate 'c3' column , repeat it 3 times and modify the 'c4' column inplace with .loc