i am looking for a way to disaggregate data from a single row in a pandas df.
My data looks like this
edit: n stands for an unspecified number, e.g. in my working dataset I have 8 plots giving me 8 x 2 = 16 columns I would like to transform.
data = {
'key':['k1', 'k2'],
'plot_name_1':['name', 'name'],
'plot_area_1':[1,2],
'plot_name_2':['name', 'name'],
'plot_area_2':[1,2],
'plot_name_n':['name', 'name'],
'plot_area_n':[1,2]
}
df = pd.DataFrame(data)

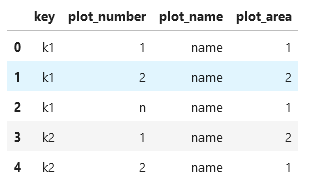
And I would like to end up here, adding an extra column to identify the plot number:
data = {
'key':['k1','k1','k1', 'k2', 'k2', 'k2'],
'plot_number':['1', '2', 'n','1', '2', 'n'],
'plot_name':['name', 'name','name', 'name','name', 'name'],
'plot_area':[1,2,1,2,1,2],
}
df = pd.DataFrame(data)
CodePudding user response:
pd.wide_to_long can do this:
In [160]: pd.wide_to_long(df, stubnames=["plot_name", "plot_area"],
i="key", j="plot_number",
sep="_", suffix=r"(?:\d |n)").reset_index()
Out[160]:
key plot_number plot_name plot_area
0 k1 1 name 1
1 k2 1 name 2
2 k1 2 name 1
3 k2 2 name 2
4 k1 n name 1
5 k2 n name 2
where
- "stubnames" are the common column prefix names to capture
- "sep" is the separator after those prefixes
- "_" in your case
- "suffix" is what's expected after the separator
- one or more digits, or literal "n" in your case; if "n" was symbolic, you can have
suffix=r"\d "there
- one or more digits, or literal "n" in your case; if "n" was symbolic, you can have
- "i" argument is the "index" (i.e., the identifier variables)
- "j" signifies the name under which the suffixes are gathered.
As an aside, we need to paranthesise the regex when multiple suffixes are possible because of the way pandas uses the suffix under the hood when constructing the regex:
regex = rf"^{re.escape(stub)}{re.escape(sep)}{suffix}$"
We see that suffix is interpolated directly, and an alternator (i.e., |) in it will see the left side as, e.g., not only \d but also what comes from stub & sep, too.
CodePudding user response:
One option is to reshape with pivot_longer from pyjanitor, using a regular expression to capture the groups:
# pip install pyjanitor
import pandas as pd
import janitor
(df
.pivot_longer(
index='key',
names_to = ('.value', 'plot_number'),
names_pattern = r"(. )_(. )")
)
key plot_number plot_name plot_area
0 k1 1 name 1
1 k2 1 name 2
2 k1 2 name 1
3 k2 2 name 2
4 k1 n name 1
5 k2 n name 2
The .value determines which parts of the columns remains as headers