I am trying to convert a metatag to plain text using the Buffer.from and .toString(). My goal is to display an array of the keywords using the .map method within my main function. But I notice some strange behavior. My map function isn't displaying the keywords correctly.
Keywords: [79, 0, 98, 0, 115, 0, 116, 0, 59, 0, 80, 0, 101, 0, 114, 0, 115, 0, 111, 0, 110, 0, 59, 0]
const buffer = Buffer.from(Keywords);
buffer:
{"data": [79, 0, 98, 0, 115, 0, 116, 0, 59, 0, 80, 0, 101, 0, 114, 0, 115, 0, 111, 0, 110, 0, 59, 0], "type": "Buffer"}
const bufferString = buffer.toString();
bufferString: Obst;Person;
after returning the bufferString to my main method: Set {"O", "", "b", "s", "t", ";", "P", "e", "r", "o", "n"}
I also tried to use .split()
const words = bufferString.split(";"); => ["Obst", "Person", ""] but when i return this array, then my map function displays only the letter O from the first keyword and no letters from the second keyword.
The strange thing is that when i create a new Array like let keywords = ["Obst", "Person", ""]; everything is working correctly.
So something must be odd with the strings coming from the buffer.
CodePudding user response:
UCS-2 is a character encoding standard in which characters are represented by a fixed-length 16 bits (2 bytes)
With the encoding known you can decode properly and get the data as expected:
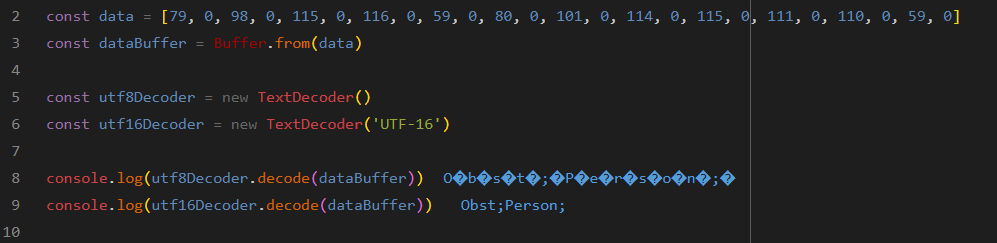
const data = [79, 0, 98, 0, 115, 0, 116, 0, 59, 0, 80, 0, 101, 0, 114, 0, 115, 0, 111, 0, 110, 0, 59, 0]
const dataBuffer = Buffer.from(data)
const utf16Decoder = new TextDecoder('UTF-16')
console.log(utf16Decoder.decode(dataBuffer)) // Obst;Person;
I think it's trying to decode as utf8 by default and getting upset at the unrenderable null bytes between every character: