I am trying to scrape this website: 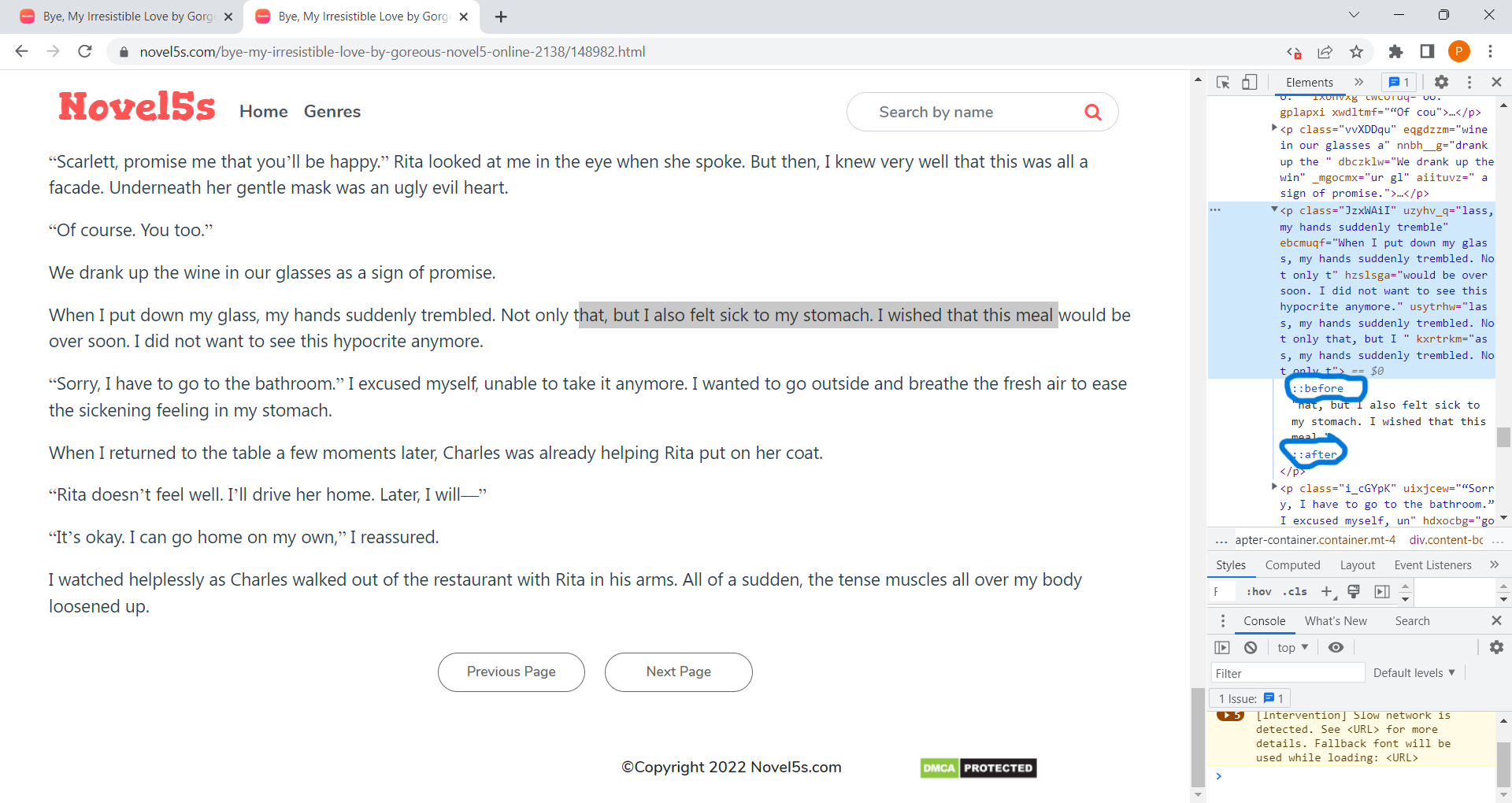
CodePudding user response:
If you inspect the page, you'll see that the text of the book is actually under the class:
So, target that class.
Now you can't just use:
soup.find_all(class_="content-book my-4")
since that would give us unnecessary <script> tags:
<div ><p> <strong>Chapter 2 Sick Feeling</strong></p><p> Scarlett’s POV:</p><p> “Anything else?” I asked in disbelief.</p><p> “We have to get up early to see Rita tomorrow,” Charles replied coldly.</p><p> “Okay.”</p><p> I was confused. I could not help but wonder if he returned just to make a point.</p><p> “I’ll sleep here tonight,” he added.</p><p> I came to my senses the instant I heard what he had said. I wanted to ask him if it was really okay for
So, instead, use a CSS selector:
for element in soup.select(".content-book.my-4 p"):
print(element.text)
This will select a <p> under the class of content-book my-4. (This is for Chapter 2, but it still works on chapter 1).
import requests
from bs4 import BeautifulSoup
URL = "https://novel5s.com/bye-my-irresistible-love-by-goreous-novel5-online-2138/148982.html"
soup = BeautifulSoup(requests.get(URL).content, "html.parser")
for element in soup.select(".content-book.my-4 p"):
print(element.text)
Output:
Chapter 2 Sick Feeling
Scarlett’s POV:
“Anything else?” I asked in disbelief.
“We have to get up early to see Rita tomorrow,” Charles replied coldly.
“Okay.”
I was confused. I could not help but wonder if he returned just to make a point.
“I’ll sleep here tonight,” he added.
I came to my senses the instant I heard what he had said. I wanted to ask him if it was really okay for him to stay here, but I decided to swallow my words instead.
“I’m afraid you’ll oversleep because of the jet lag,” he
...
CodePudding user response:
The order of the hidden text seems to be encoded in the style element in the webpage html, just below the div element containing all paragraphs (see screenshot).
The codes in this style element seem to correspond to the class and randomized tags in the paragraph elements that you have trouble with parsing.
My suggestion would be to parse this style element, extract the classes and tags in the right order, and parse those from the paragraph elements to get the complete paragraphs.
It would still require some parsing and decoding, but I hope this helps!
Screenshot: The element that presumably encodes the text order contained in randomized tags
{kind=link}